
The End of "We'll Build It In-House": 5 Document Processing Predictions for 2026
Why this is the year enterprises stop reinventing the wheel on document infrastructure.
If you've spent any time in enterprise software, you've heard this story before: an engineering team gets tasked with extracting data from documents. "How hard can it be?" someone asks. "We'll just use GPT."
Six months later, they've built an entire team around it—and they're still not done.
2026 is the year this changes. Here's why.
📊 1. Document Processing Becomes Invisible Infrastructure
Gartner predicts 40% of enterprise applications will feature AI agents by end of 2026—up from less than 5% in 2025. That's an 8x jump in one year.
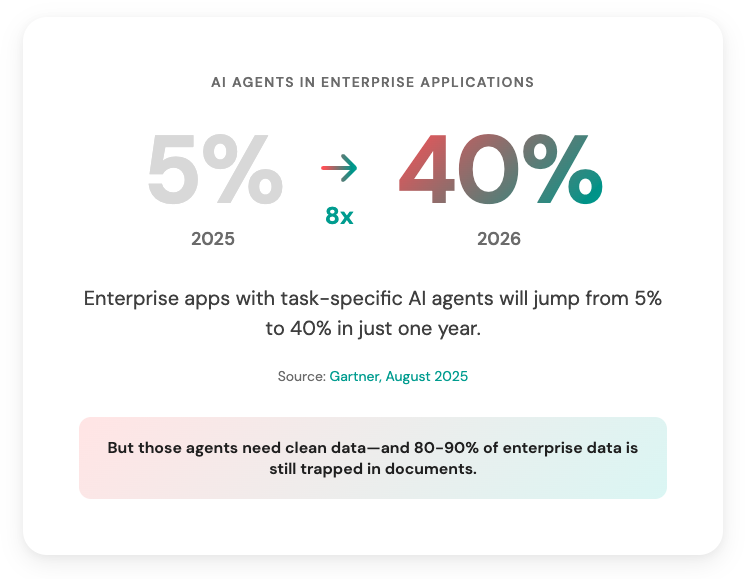 Source: Gartner, August 2025
Source: Gartner, August 2025
But here's the quiet part:
🔑 Those agents need clean, structured data to work with. And 80-90% of enterprise data is still trapped in unstructured documents.
Document processing isn't a standalone project anymore. It's becoming invisible infrastructure—something you expect to just work, like authentication or payments.
Organizations won't run "document extraction initiatives." They'll expect documents to be understood, classified, and routed automatically as part of everyday workflows.
⏱️ 2. The "Simple Prompt" Plateau Hits Every Team
We've watched dozens of teams follow the same arc:
- Week 1: "We'll just send the PDF to ChatGPT with a prompt." (sound familiar?)
- Week 4: "Okay, tables aren't extracting correctly."
- Week 8: "Why is it pulling the sidebar text before the main content?"
- Week 12: "We need a way to flag uncertain results for human review."
- Month 6: "We've built a document processing team."
 Every team follows the same arc
Every team follows the same arc
This isn't a failure of AI. It's a failure to recognize that document parsing is a solved problem—solved by teams who've spent years on the edge cases.
The failure modes are always the same:
- Multi-column layouts break extraction
- Reading order gets scrambled
- Tables come out garbled
- No way to catch errors before they hit downstream systems
⚠️ A company that spends 6 months and roughly €400K on an internal solution could have shipped two product features instead.
🏭 3. Specialized Tools Replace One-Size-Fits-All Approaches
The "throw everything at one AI model" approach is dying.
In 2026, the best document processing systems use the right tool for each job:
- One component identifies where tables are
- Another extracts the data from them
- Another handles handwriting
- Another classifies the document type
🔧 Think of it like a factory floor. You don't use the same machine to cut metal, weld it, and paint it. Same principle.
This matters for reliability. A single model failing means everything fails. Specialized components can be monitored, tested, and improved independently—which is why purpose-built platforms consistently outperform DIY solutions on accuracy and uptime.
Teams that have been building document infrastructure for years already work this way. Teams trying to build it themselves are starting from zero—and rediscovering problems that were solved in 2019.
🛒 4. Buy vs. Build Finally Tips—For Non-Core Problems
Here's the framework that's emerging:
💡 Build AI where it differentiates you. Buy AI where it unblocks you.
Document processing rarely differentiates anyone. Whether you're in insurance, finance, logistics, or healthcare—turning documents into structured data is a prerequisite for the actual work, not the work itself.
The math is brutal:
- A senior engineer costs $200K+ fully loaded
- A 6-month document processing project that could have been solved with an API isn't just expensive
- It's 6 months your actual product didn't ship
2026 is the year CFOs start asking: "Why do we have three engineers working on PDF parsing?"
🔒 5. Compliance Becomes a Forcing Function
KYC failures cost banks billions in sanctions annually. Insurance claims with incorrect extractions create liability. Healthcare documents with missed fields create patient safety issues.
Enterprises are realizing that homegrown document processing isn't just inefficient—it's a compliance risk.
When the auditors ask "how do you know this extraction was correct?", you need answers:
- Audit trails
- Confidence flags
- Validation rules
- Version history
Building this from scratch means building a compliance infrastructure from scratch.
⚠️ This is especially true in Europe and other regulated markets, where GDPR, industry-specific regulations, and stricter enforcement mean "it mostly works" isn't acceptable. You need documented processes, not a collection of scripts held together by hope.
🎯 The Bottom Line
Turning documents into data is hard. Not "weekend project" hard. Not "we'll figure it out" hard. Hard enough that it should be someone's entire focus.
At anyformat, that's exactly what it is. We built our platform around three things enterprises actually care about:
 The three pillars of enterprise document infrastructure
The three pillars of enterprise document infrastructure
Document infrastructure is our core—not a side project, not an internal tool we decided to sell.
🚀 Ready to Stop Reinventing the Wheel?
The question for 2026 isn't "can we build document processing?"
You can. The question is: should you?
Your engineers have products to ship. Let document infrastructure be someone else's core.
