
Más allá de la precisión: las métricas de Document AI que realmente predicen el éxito en producción
De piloto a producción · 02
La primera pregunta que nos hace cada cliente potencial: "¿Cuál es vuestra tasa de precisión?"
Mi respuesta: "¿En qué documentos? ¿Medida cómo? ¿Y qué ocurre cuando nos equivocamos?"
Eso suele cambiar la conversación.
En el primer artículo de esta serie, escribí sobre la trampa de la extracción — el patrón en el que las empresas invierten en automatización de documentos y acaban con una cola de validación en lugar de una solución. Dos de cada tres nuevos contratos de IDP son sustituciones de herramientas que ya habían fallado. La respuesta me confirmó que este tema toca una fibra sensible. Muchos de vosotros lo estáis viviendo.
Este artículo trata sobre por qué esto ocurre a nivel de medición. El sector adoptó una métrica — la precisión — que suena rigurosa pero que en realidad oculta lo que realmente importa.
Por qué los benchmarks de precisión en document AI son engañosos
Un ejemplo típico: "Nuestro sistema alcanza un 97,3% de precisión en la extracción de facturas."
Eso suena exacto. Suena fiable. No es ninguna de las dos cosas.
Lo que ese número normalmente significa es que el proveedor ejecutó su sistema contra un conjunto de datos de referencia seleccionado — documentos limpios, formatos estándar, idiomas comunes — y midió cuántos campos acertó. El conjunto de datos se diseñó para ser representativo. No lo es. No puede serlo. Vuestros documentos son vuestros.
La brecha entre el rendimiento en benchmarks y el rendimiento en producción es el espacio donde vive la trampa de la extracción. La evaluación de IDP de Everest Group en 2024 reveló que los compradores empresariales reportan consistentemente una caída de 15 a 25 puntos porcentuales entre la precisión que declara el proveedor y el rendimiento real en producción.
Un sistema puede tener un 99% de precisión en facturas estándar de vuestros 50 principales proveedores — los documentos limpios y comunes. Pero puede tener un 60% de precisión en la larga cola: los proveedores puntuales, las órdenes de compra manuscritas, los contratos escaneados de hace tres años que alguien necesita conciliar.
Si hacéis la media, obtenéis un respetable 94%. Poned eso en producción y tres personas de vuestro equipo se pasan el día corrigiendo errores que el sistema "94% preciso" produjo. Según los benchmarks de IOFM, el coste medio de gestionar manualmente una excepción de factura es de 8 a 15 dólares. Con 500 excepciones al día, eso supone de 1,5 a 2,7 millones de dólares anuales en costes ocultos de retrabajo. La media mintió.
Un benchmark te dice lo bien que funciona un sistema en condiciones controladas. La producción te dice lo bien que funciona en las tuyas.
Tasa de fallos silenciosos: la métrica de IDP que realmente importa
Hay una pregunta que he empezado a hacer a todas las empresas con las que hablo: "Cuando vuestro sistema actual se equivoca, ¿cómo os enteráis?"
Las respuestas se dividen en dos categorías.
Algunos se enteran porque el sistema señala la incertidumbre — le dice al equipo "no estoy seguro de esto, por favor revisadlo". Eso es manejable. Molesto a escala, pero manejable.
La mayoría se entera aguas abajo. El número incorrecto entra en el ERP. Una factura se paga con el importe equivocado. Un duplicado se cuela. Un código fiscal se aplica mal. Alguien de contabilidad lo descubre durante la conciliación, o peor aún, un auditor lo descubre durante una revisión.
Este es el fallo silencioso — el sistema extrae un valor, lo presenta con aparente confianza, y está equivocado. Nadie lo detectó porque el sistema no señaló que algo iba mal.
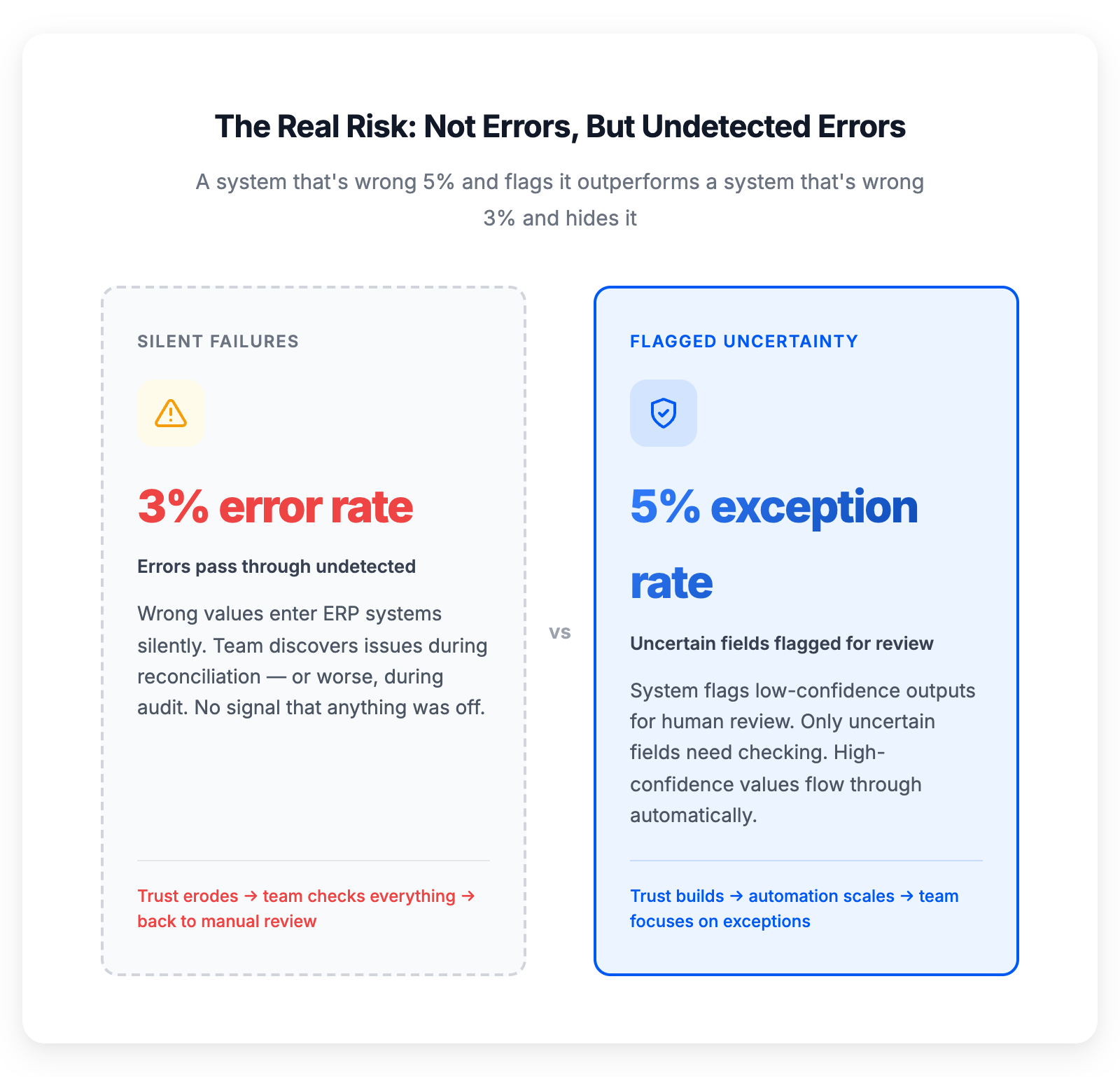 Una tasa de excepciones más alta con incertidumbre señalada supera a una tasa de error más baja con fallos silenciosos
Una tasa de excepciones más alta con incertidumbre señalada supera a una tasa de error más baja con fallos silenciosos
Los fallos silenciosos son los errores más costosos en la automatización de documentos. No porque cada uno sea catastrófico (normalmente), sino porque erosionan la confianza. Después de unos cuantos fallos silenciosos, el equipo deja de confiar en el sistema. Empiezan a revisarlo todo de nuevo. Volvéis a la cola de validación. La automatización ha fallado no porque no funcione, sino porque nadie se la cree cuando sí funciona.
La métrica que importa no es "con qué frecuencia acierta el sistema". Es "con qué frecuencia se equivoca y no lo sabe".
Un sistema que se equivoca el 5% de las veces y señala cada resultado incierto es mucho más útil que un sistema que se equivoca el 3% de las veces y nunca te lo dice.
Puntuación de confianza a nivel de campo: la capa que falta en el procesamiento de documentos
Cuando construimos anyformat, la decisión arquitectónica más importante que tomamos no fue qué modelo usar ni cómo analizar PDFs. Fue esta: cada valor extraído debe llevar una puntuación de confianza, y esas puntuaciones deben estar calibradas contra juicios humanos reales.
¿Qué significa esto en la práctica?
El sistema no dice simplemente "el total de la factura es 14.320 €". Dice "el total de la factura es 14.320 €, y tengo un 98,2% de confianza en ello". Para otro campo del mismo documento, podría decir "el número de pedido es AT-2024-0892, y tengo un 71% de confianza".
El campo con 98,2% se aprueba automáticamente. El campo con 71% se dirige a un revisor humano. El revisor no comprueba todo el documento — solo el campo incierto. Ve el valor, ve la puntuación de confianza, y (como comentaré en el próximo artículo) ve exactamente dónde en el documento lo leyó el sistema.
Esto cambia por completo la economía del procesamiento de documentos. En lugar de revisar el 100% de los campos extraídos, vuestro equipo revisa quizás entre el 5 y el 15%, dependiendo de la calidad de los documentos. El resto fluye automáticamente — no porque hayáis confiado ciegamente en la IA, sino porque la IA se ha ganado la confianza campo por campo.
Pero aquí es donde la cosa se pone precisa, y donde la mayoría de los proveedores de IDP recortan.
Por qué la calibración de confianza separa el IDP de producción de los productos de demostración
Una puntuación de confianza solo significa algo si está calibrada. Cuando el sistema dice "95% de confianza", eso debería corresponderse con acertar el 95% de las veces en los campos donde reporta ese nivel de confianza. No el 88%. No el 91%. Noventa y cinco.
Calibrar las puntuaciones de confianza requiere un corpus sustancial de datos etiquetados por humanos. Se necesitan personas que anoten los valores correctos de miles de documentos, y luego comparar los resultados y niveles de confianza del sistema con esas etiquetas humanas. El resultado es una curva de calibración — una correspondencia entre lo que el sistema dice que es su confianza y lo que realmente es.
 La confianza calibrada significa que vuestros umbrales de aprobación automática funcionan como se espera
La confianza calibrada significa que vuestros umbrales de aprobación automática funcionan como se espera
Un sistema bien calibrado produce una línea diagonal: 70% de confianza = 70% de aciertos. 90% de confianza = 90% de aciertos. 99% de confianza = 99% de aciertos.
Un sistema no calibrado — que es lo que producen la mayoría de las herramientas — podría decir "95% de confianza" cuando la precisión real en ese umbral es del 82%. Vuestro equipo establece un umbral de aprobación automática en el 95%, esperando un 5% de errores. Obtiene un 18%. La confianza se derrumba. De vuelta a la cola de validación.
Hemos escrito en detalle sobre cómo puntuamos la confianza en datos estructurados, incluyendo el análisis de probabilidad a nivel de token y el enfoque multiseñal que hace posible la calibración.
La confianza sin calibración es decoración. Hace que el resultado parezca fiable sin serlo realmente.
5 métricas para evaluar document AI en producción
Si estáis evaluando soluciones de procesamiento inteligente de documentos — o intentando entender por qué vuestro sistema actual no rinde — estas son las métricas que realmente predicen el éxito en producción:

1. Tasa de procesamiento directo (STP). ¿Qué porcentaje de documentos requiere cero intervención humana? No "cero errores" — cero interacciones. El documento entra, se procesa, y el resultado estructurado fluye a vuestro sistema sin que nadie lo mire. Esta es la métrica que se traduce directamente en ahorro de personal y velocidad de procesamiento. El benchmark de IDP de ABBYY en 2024 sitúa la tasa media de STP del sector entre el 40 y el 60% para el procesamiento de facturas — los mejores alcanzan más del 85%.
2. Tasa de excepciones por tipo de campo. No todos los campos son iguales. Los números de factura y las fechas tienden a tener alta confianza. Las descripciones de líneas de detalle y los códigos fiscales tienden a ser más bajos. Entender la tasa de excepciones por tipo de campo os dice dónde es fuerte el sistema, dónde necesita ayuda y dónde concentrar los esfuerzos de mejora.
3. Precisión de la calibración de confianza. ¿Un 90% de confianza realmente significa un 90% de aciertos? Si no podéis verificarlo, vuestras puntuaciones de confianza son cosméticas. Pedid a vuestro proveedor su curva de calibración. Si no tiene una, sus puntuaciones de confianza no están calibradas.
4. Coste por documento procesado. Esta es la métrica del CFO. Incluye todo: coste de software, coste de infraestructura, tiempo de revisión humana, tiempo de corrección de errores y coste aguas abajo de los errores que se cuelan. Un sistema con menor "precisión" pero mejor puntuación de confianza puede tener un coste por documento drásticamente inferior — porque dirige la atención humana solo donde se necesita.
5. Tasa de fallos silenciosos. ¿Con qué frecuencia se aprueba automáticamente un valor incorrecto? Esto debería monitorizarse mensualmente y mostrar una tendencia descendente. Si no baja, el sistema no está aprendiendo de las correcciones.
La conversación honesta sobre la precisión de document AI
Seré directo con algo. anyformat no es perfecto en todos los documentos. Ningún sistema lo es. La diferencia es que sabemos dónde somos imperfectos, y os lo decimos.
Nuestras puntuaciones de confianza están calibradas contra conjuntos de datos etiquetados por humanos que abarcan miles de tipos de documentos entre facturas, contratos, órdenes de compra y declaraciones aduaneras. Cuando decimos 97% de confianza, lo decimos en serio — lo hemos verificado contra miles de anotaciones humanas. Cuando el sistema se encuentra con un documento realmente difícil — mala calidad de escaneo, diseño inusual, escritura a mano ambigua — la confianza baja y el campo se marca para revisión.
Eso no es una limitación. Así es como funciona la confianza.
Las empresas que escapan de la trampa de la extracción no tienen una IA más precisa. Tienen una IA que es honesta sobre sus propias limitaciones. Paradójicamente, esa honestidad es lo que hace posible la automatización real — porque podéis establecer umbrales, definir reglas y construir flujos de trabajo en torno a un sistema cuya incertidumbre entendéis.
Un sistema que siempre está seguro es un sistema en el que nunca podéis confiar del todo. Un sistema que sabe cuándo no sabe — eso es infraestructura sobre la que construir.
Preguntas frecuentes
¿Qué es el procesamiento directo (STP) en document AI?
El procesamiento directo mide el porcentaje de documentos que fluyen a través de un sistema IDP sin intervención humana alguna — sin revisión manual, sin correcciones. Es el mejor indicador individual del ROI real de la automatización, porque se traduce directamente en velocidad de procesamiento y ahorro de costes.
¿Qué es la calibración de confianza en el procesamiento inteligente de documentos?
La calibración de confianza significa que las puntuaciones de confianza reportadas por un sistema coinciden con la precisión en el mundo real. Cuando un sistema calibrado dice "95% de confianza", acierta el 95% de las veces en ese umbral. Los sistemas no calibrados pueden reportar un 95% de confianza mientras solo aciertan entre el 80 y el 85% de las veces, lo que provoca errores inesperados en producción.
¿Cómo se mide la tasa de fallos silenciosos en el procesamiento de documentos?
La tasa de fallos silenciosos registra con qué frecuencia un sistema extrae un valor incorrecto sin marcarlo para revisión humana. Se mide tomando muestras de los resultados aprobados automáticamente y comparándolos con la verdad verificada por humanos. Los sistemas de primera categoría aspiran a una tasa de fallos silenciosos inferior al 0,5%.
¿Por qué los benchmarks de document AI no reflejan el rendimiento en producción?
Los benchmarks utilizan conjuntos de datos seleccionados con documentos limpios y estándar. Los entornos de producción incluyen casos extremos: mala calidad de escaneo, anotaciones manuscritas, contenido multilingüe, diseños no estándar. La brecha entre la precisión en benchmarks y en producción es típicamente de 15 a 25 puntos porcentuales.
Próximo en la serie: Si no puedes señalarlo, no puedes confiar en ello — por qué la fundamentación visual es la base de un document AI auditable.
Anteriormente: La paradoja del papel: por qué Document AI todavía no ha sustituido el trabajo manual — lo que más de 100 conversaciones con empresas me enseñaron sobre document AI.
Compara anyformat: vs Azure Document Intelligence · vs Extend AI · vs ChatGPT, Claude y Gemini · Todas las comparaciones →
Juan Huguet CEO y cofundador, anyformat.ai
