
The Paper Paradox: Why Document AI Still Hasn't Replaced Manual Work
From Pilot to Production · 01
61% of intelligent document processing workflows still involve paper. Nearly half of enterprises expect their paper volumes to go up next year. Not down. Up.
 Source: AIIM / Deep Analysis · Market Momentum Index: IDP Survey 2025 · n=600
Source: AIIM / Deep Analysis · Market Momentum Index: IDP Survey 2025 · n=600
That data comes from a 2025 AIIM and Deep Analysis survey of 600 enterprises across the US and Europe. All with revenues above $10M, more than 500 employees, spanning finance, healthcare, manufacturing, insurance, energy, and government. These are not companies that haven't heard of AI. 78% of them are already operational with it. 65% are actively pursuing new document processing initiatives.
They know the technology exists. They've bought it. Many of them are buying it again.
 Source: AIIM / Deep Analysis · Market Momentum Index: IDP Survey 2025
Source: AIIM / Deep Analysis · Market Momentum Index: IDP Survey 2025
Two out of three new IDP deals are replacements of tools that already failed. That's not an adoption problem. That's a trust problem. And it's the bill for an industry that optimized for demos instead of production.
80% of enterprise data is still trapped in documents
Gartner and IDC both estimate that roughly 80% of enterprise data is unstructured: emails, PDFs, scanned forms, contracts, images. Only about 18% of organizations are effectively using any of it. McKinsey puts the opportunity at 40% lower processing costs and 70% faster turnaround when document workflows are actually automated.
But the AIIM numbers tell you what "actually automated" looks like in practice. Fax machines are still part of the process in 37% of cases. Not just in US healthcare: the stat holds across all surveyed regions. Over half of respondents say they lack the technical expertise to make their IDP investments work.
And when enterprise leaders are asked what matters most in their automation strategy, accuracy wins. Not speed. Not cost reduction. Accuracy. Because without it, you're just making mistakes faster. The experimentation budget is gone. Boards want ROI within the fiscal year. Deliver measurable impact or lose funding. That's the climate.
The question was never "can AI read a document?" It's "can AI read your documents, reliably, at scale, without someone checking its work every time?"
The extraction trap: why document extraction fails in production
A vendor demos their platform. A clean PDF invoice goes in, structured JSON comes out. The accuracy metric says 98%. The buyer signs.
Then production hits.
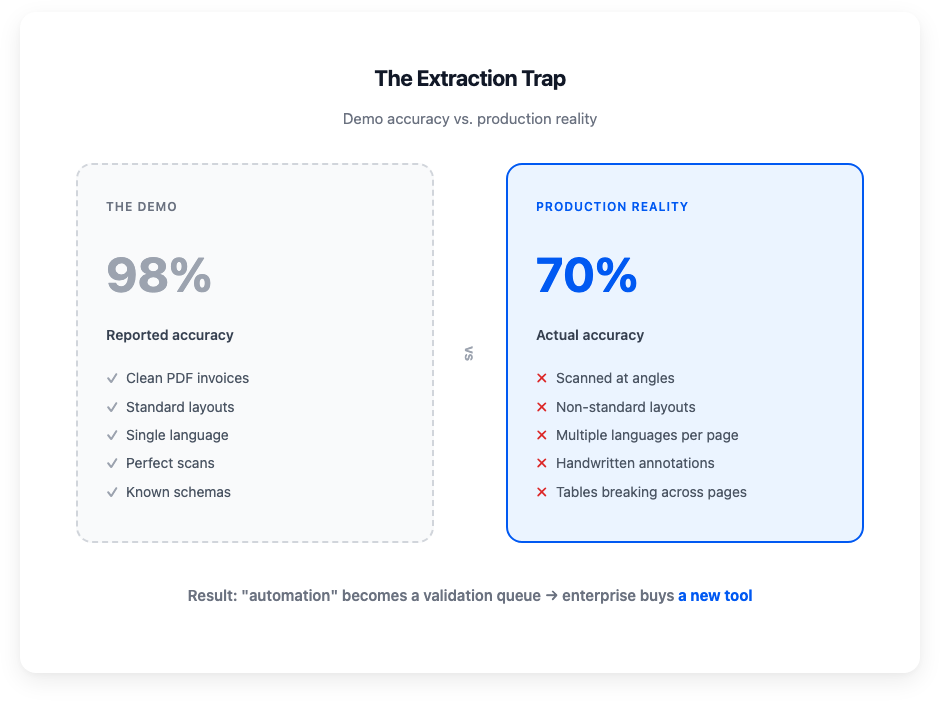 Every IDP buyer recognizes this pattern
Every IDP buyer recognizes this pattern
Real documents are not demo documents. They're scanned at angles, arrive in three languages on the same page, have handwritten annotations, non-standard layouts, tables that break across pages. The system that scored 98% on the benchmark scores 70% on actual client data. The "automation" becomes a validation queue. Humans correcting what the machine got wrong, one field at a time.
The tool didn't fail because AI is bad. It was built for clean inputs and deployed against messy ones. It worked in the demo. It didn't work in production.
So the enterprise buys a new tool. 66% replacement rate.
Before you become a replacement statistic
If you're evaluating document processing infrastructure, whether building in-house, stitching together open-source parsers, or buying a platform, the AIIM data should change what you ask for.

01 · "What happens when the system is wrong?"
Every vendor will claim >95% accuracy. That number means nothing without context. Accuracy on which documents? Measured how? At what confidence threshold? What matters is field-level confidence scoring: the system telling you how certain it is about each extracted value. "99% confident about the invoice total, 62% confident about the PO number" gives your team something to act on. A system that outputs values and hopes for the best is why most workflows are still tied to paper.
02 · "Can I see where in the document this came from?"
Visual grounding links every extracted field back to its exact location in the source document. This is what makes AI decisions auditable. With EU regulations tightening (ViDA, DORA, country-specific e-invoicing mandates), you can't govern what you can't trace. If your extraction system can't show you which region on which page produced a given value, you don't have an audit trail. You have a black box.
03 · "Does this work on my actual data, today?"
Not a demo dataset. Not a benchmark. Your documents: the messy ones, the ones in three languages with handwritten notes and broken layouts. If a vendor can't prove performance on your real data before you sign, you're buying a pilot destined for the 66% replacement cycle. Ask for a proof of concept with your ugliest documents. That test tells you everything the sales deck won't.
What actually separates production systems from demo-ware
The IDP industry frames its evolution as moving from data entry to "decision engine." That's directionally right, but I'd frame it differently.
The divide is between systems that work in production and systems that work in demos. Tools that handle the clean 80% vs. infrastructure that handles the ugly 100%. Extraction that needs human validation vs. extraction that earns trust through transparency: confidence scores, visual grounding, audit trails.
The enterprises replacing their IDP systems aren't stuck because AI is bad. They're stuck because the industry shipped demo-quality tools and called them enterprise-ready. The fix isn't a smarter model. It's a more honest one. A system that tells you what it knows, what it doesn't, and where to look.

That's what we're building at anyformat. Field-level confidence scoring, visual grounding back to the source document, >97% accuracy on real client data in production. No training required. The kind of system where "it works on the demo" and "it works on your data" mean the same thing.
This is the first post in "From Pilot to Production", a series about what document AI looks like when it has to work for real. Next up: why accuracy benchmarks are broken and what should replace them.
Send us your ugliest documents →
See how anyformat compares: vs Google Document AI · vs AWS Textract · vs ABBYY · vs Reducto · All comparisons →
Juan Huguet · CEO & Co-founder, anyformat.ai · Nuclear Engineer · Physics PhD
