
Por qué GPT por sí solo no es suficiente para la extracción real de documentos
Una mirada práctica a los límites de los LLM en la Inteligencia Documental
Nota del editor (julio de 2026): este artículo es anterior a nuestro benchmark completo de producción. Para los números actuales frente a GPT-5.6, Gemini 3.5 Flash y Claude Opus 4.8 con más de 1.000 documentos reales, lee La demo funciona. Producción es el benchmark.
En anyformat, nuestra misión es sencilla: convertir cualquier archivo en los datos que necesitas.
Los grandes modelos de lenguaje como GPT han transformado nuestra forma de interactuar con el texto. Resumen, traducen y generan contenido con una fluidez impresionante.
Pero cuando se trata de convertir documentos del mundo real — facturas, albaranes, planes de proyecto — en datos estructurados y fiables, la idea de "simplemente usar GPT" se desmorona rápidamente.
🧩 Los documentos reales son complejos — y eso importa
Los documentos reales no son solo texto plano. Combinan:
- párrafos
- jerarquías visuales
- sellos y firmas
- tablas
- diagramas y figuras
- maquetaciones mixtas
Intentar extraer todo en una sola pasada del modelo (extracción en un solo paso) a menudo falla de formas sutiles e impredecibles.
¿Por qué?
Porque el modelo debe realizar simultáneamente la comprensión del diseño, la interpretación semántica y la preservación de la estructura — y hasta el mínimo ruido puede descarrilar el resultado.
🧪 ¿Puede GPT hacer OCR? Sí. ¿Puedes confiar en él? A veces.
Todo pipeline robusto de documentos comienza con un paso esencial:
OCR — convertir un PDF o escaneo en texto legible por máquina (Markdown/HTML).
Los LLM multimodales pueden realizar OCR, pero en la práctica observamos de forma constante:
- Ruido menor en el diseño → interpretaciones erróneas graves
- Escaneos de bajo contraste → bloques de texto fusionados o parcialmente ausentes
- Tablas y figuras → aplanadas o malinterpretadas como prosa
- Contexto visual → ignorado
Y el problema clave:
🔄 Cuando el OCR es defectuoso, cada paso posterior de extracción está condenado al fracaso.
¿Una tabla malinterpretada como un párrafo? Imposible de analizar.
¿Un encabezado perdido? La estructura semántica se derrumba.
¿Un número incorrecto? La lógica de negocio se rompe.
Estos no son casos extremos — son factores decisivos para las empresas que intentan automatizar flujos de trabajo solo con LLM.
📉 Tablas: el punto débil silencioso de los pipelines documentales
Las tablas comprimen significado multidimensional en estructuras dependientes del diseño.
Su interpretación depende no solo del texto, sino de:
- posiciones de filas y columnas
- encabezados
- celdas combinadas
- señales estructurales implícitas
Incluso los LLM más potentes fallan frecuentemente al:
- 🔄 Mantener la estructura — las filas desaparecen, los encabezados se fusionan
- 🧱 Preservar el diseño — el formato ambiguo se convierte en prosa
- ⚠️ Garantizar la coherencia — tablas casi idénticas producen resultados diferentes
📊 Benchmark: Precisión en tablas entre distintos LLM
Evaluamos ~1.130 tablas de más de 1.000 documentos reales, derivados del GetOmni OCR Benchmark [1].
El conjunto de datos es enormemente valioso (¡gracias, GetOmni!), pero no es perfecto:
- Los diseños repetitivos reducen la diversidad y pueden inflar el rendimiento
- Los formatos de tabla mixtos (Markdown + HTML) complican la evaluación
En nuestra investigación, muchos fallos se originan antes de la extracción — en el paso de análisis de Markdown. Markdown simplemente no puede representar estructuras de tabla complejas.
En anyformat, validamos y corregimos manualmente el HTML de referencia (ground truth) para garantizar una evaluación coherente.
Comparamos las tablas HTML predichas utilizando la distancia de edición normalizada [2].
A continuación se muestra un ejemplo de nuestra precisión en la extracción de tablas en un solo paso entre distintos LLM:
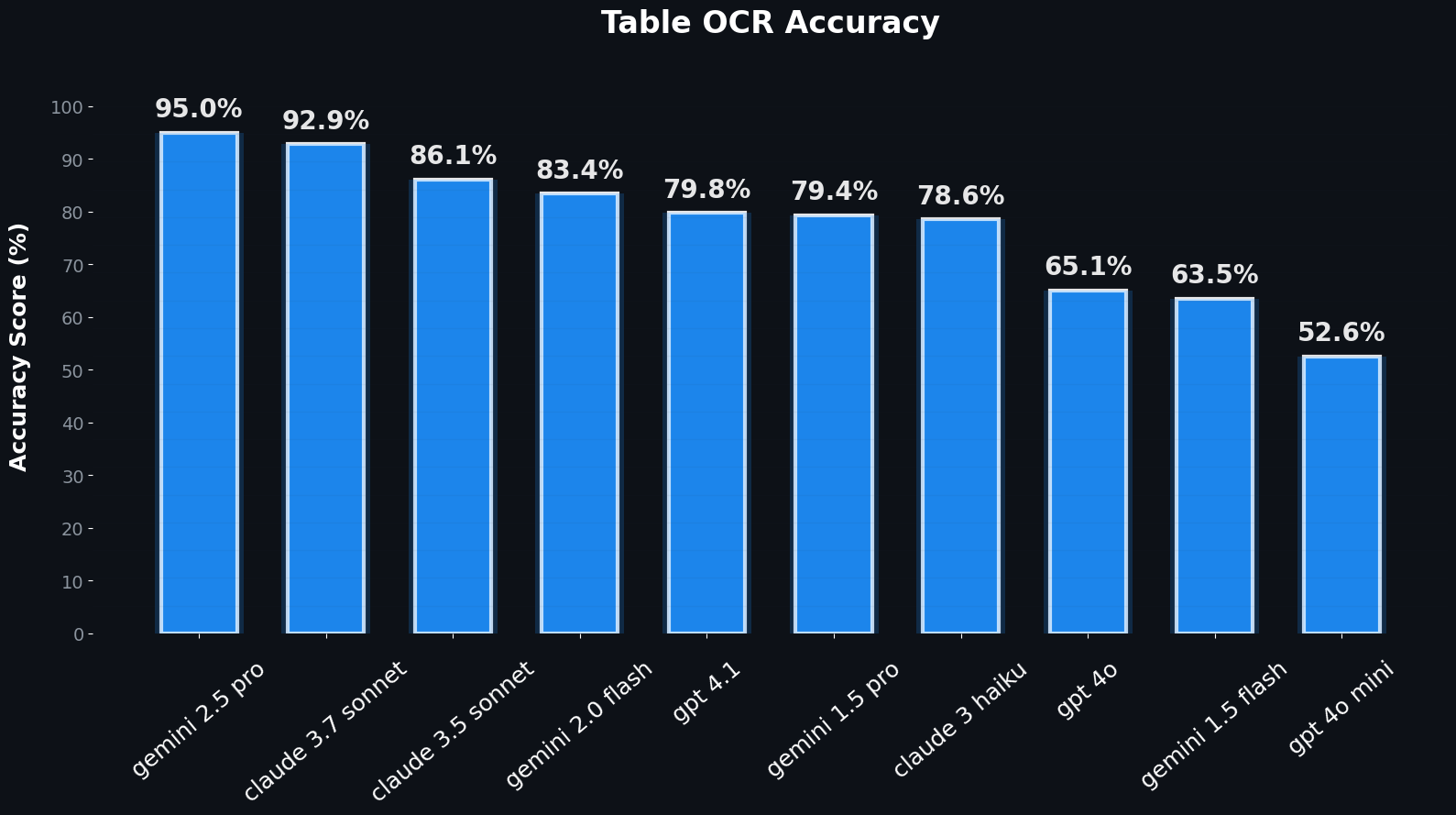
Figura 1: Precisión de OCR en la extracción de tablas en un solo paso entre varios LLM, utilizando la distancia de edición normalizada entre el HTML predicho y el de referencia (GT).
Conclusiones clave:
- La precisión varía drásticamente entre modelos
- Los modelos más pequeños frecuentemente rinden por debajo de lo esperado
- Algunos modelos grandes (como Gemini Pro) destacan — pero pueden ser excesivos
Entonces, ¿cómo se maximiza la precisión sin reventar el presupuesto de costes?
🛠️ Nuestro enfoque: descomponer antes de extraer
En anyformat, evitamos las llamadas monolíticas y frágiles a un solo modelo.
En su lugar, nuestro agente de IA orquesta la extracción, descomponiendo cada documento en sus partes constituyentes.
Nuestro pipeline multietapa consciente de la estructura incluye:
- Mejora previa al OCR
Contraste, eliminación de ruido, mejoras de DPI - Segmentación semántica
Identificación de párrafos, tablas, figuras, notas a pie de página - Detección de elementos críticos
Sellos, firmas, marcadores visuales - Enrutamiento a rutinas de extracción especializadas
Utilizando prompts de LLM adaptados por tipo de elemento - Validación y reconciliación Postprocesamiento, puntuación de confianza, corrección de errores
Esta descomposición garantiza:
- El ruido y los artefactos de diseño se filtran de forma temprana
- Las alucinaciones disminuyen
- La tarea del modelo queda acotada y es fiable
Incluso los LLM de propósito general rinden mucho mejor una vez que la tarea de extracción está correctamente enmarcada.

Figura 2: Ejemplo de un diseño de documento complejo con múltiples elementos interrelacionados — que demuestra por qué la segmentación es crucial.
🛠️ De hacerlo tú mismo a tenerlo resuelto
Algunos equipos intentan construir sus propios pipelines de extracción basados en LLM.
Unos pocos lo consiguen — tras meses de experimentación, ingeniería y un doloroso control de calidad.
La mayoría de los equipos no disponen de ese tiempo.
anyformat no es un servicio. Es un producto.
Un motor de extracción a nivel de producción que funciona desde el primer día.
No necesitas construir tu propia plataforma de inteligencia documental.
Necesitas una que funcione.
🚀 ¿Quieres verlo en acción?
Permítenos probar anyformat con tus documentos.
Descubre cómo es una extracción precisa.
📧 info@anyformat.ai 🌐 anyformat.ai
Compara anyformat: vs ChatGPT, Claude y Gemini · vs LlamaParse · vs Unstructured · Todas las comparaciones →
🧾 Resumen de la metodología
- Documentos analizados: más de 1.000 archivos reales [1]
- Tablas evaluadas: ~1.130, con HTML validado manualmente
- Métrica: Distancia de edición normalizada [2]
- Modelos: Claude 3.7 Sonnet, Claude 3.5 Sonnet, Claude 3 Haiku, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 2.0 Flash, Gemini 2.5 Pro, GPT-4o, GPT-4o mini, GPT-4.1
📚 Bibliografía
[1] getOmni.ai. (2024). OCR Benchmark Dataset. Hugging Face.
[2] Zhong, Xu, et al. "Image-based table recognition: data, model, and evaluation." ECCV. Springer, 2020.
