
Beyond Accuracy: The Document AI Metrics That Actually Predict Production Success
From Pilot to Production · 02
The first question every prospect asks us: "What's your accuracy rate?"
My answer: "On which documents? Measured how? And what happens when we're wrong?"
That usually changes the conversation.
In the first post of this series, I wrote about the extraction trap — the pattern where companies invest in document automation and end up with a validation queue instead of a solution. Two out of three new IDP deals are replacements of tools that already failed. The response told me this hits a nerve. Many of you are living it.
This post is about why it happens at the measurement level. The industry adopted a metric — accuracy — that sounds rigorous but actually hides the thing that matters most.
Why document AI accuracy benchmarks are misleading
Here's a typical claim: "Our system achieves 97.3% accuracy on invoice extraction."
That sounds precise. It sounds trustworthy. It is neither.
What that number usually means is that the vendor ran their system against a curated benchmark dataset — clean documents, standard formats, common languages — and measured how many fields it got right. The dataset was designed to be representative. It isn't. It can't be. Your documents are yours.
The gap between benchmark performance and production performance is the space where the extraction trap lives. Everest Group's 2024 IDP assessment found that enterprise buyers consistently report a 15–25 percentage point drop between vendor-claimed accuracy and real-world production performance.
A system might be 99% accurate on standard invoices from your top 50 suppliers — the clean, common documents. But it might be 60% accurate on the long tail: the one-off suppliers, the handwritten purchase orders, the scanned contracts from three years ago that someone needs to reconcile.
Average those together and you get a respectable 94%. Put that in production and three people on your team spend their days fixing errors that the "94% accurate" system produced. According to IOFM benchmarks, the average cost to manually handle an invoice exception is $8–$15. At 500 exceptions per day, that's $1.5M–$2.7M annually in hidden rework costs. The average lied.
A benchmark tells you how well a system performs under controlled conditions. Production tells you how well it performs under yours.
Silent failure rate: the IDP metric that actually matters
There's a question I've started asking every company I talk to: "When your current system gets something wrong, how do you find out?"
The answers fall into two categories.
Some find out because the system flags uncertainty — it tells the team "I'm not sure about this one, please check." That's manageable. Annoying at scale, but manageable.
Most find out downstream. The wrong number makes it into the ERP. An invoice gets paid at the wrong amount. A duplicate slips through. A tax code is misapplied. Someone in accounting discovers it during reconciliation, or worse, an auditor discovers it during a review.
This is the silent failure — the system extracts a value, presents it with apparent confidence, and it's wrong. Nobody caught it because the system didn't signal that anything was off.
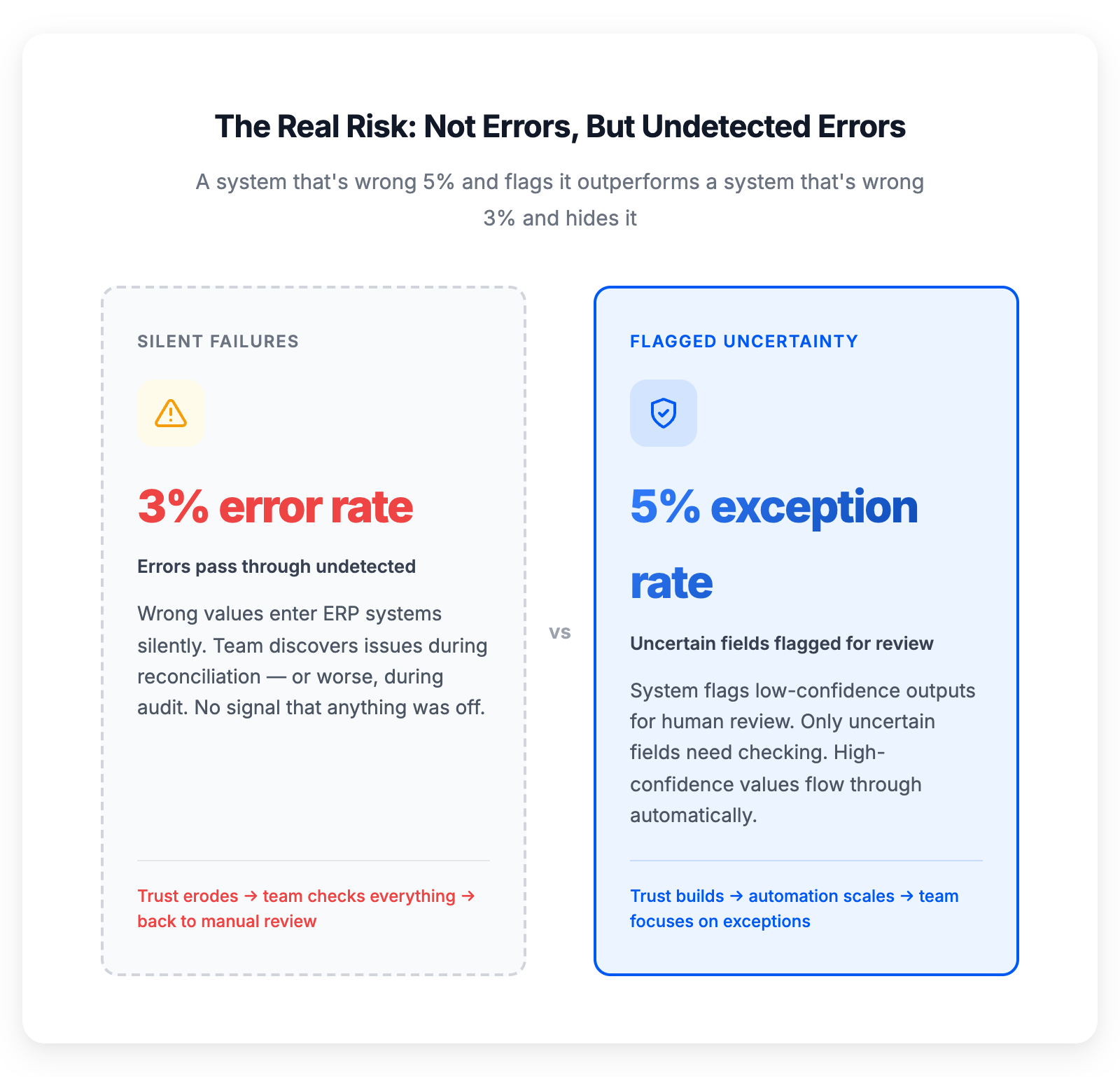 A higher exception rate with flagged uncertainty beats a lower error rate with silent failures
A higher exception rate with flagged uncertainty beats a lower error rate with silent failures
Silent failures are the most expensive errors in document automation. Not because any single one is catastrophic (usually), but because they erode trust. After a few silent failures, the team stops trusting the system. They start checking everything again. You're back to the validation queue. The automation has failed not because it doesn't work, but because nobody believes it when it does.
The metric that matters isn't "how often is the system right." It's "how often is it wrong and doesn't know it."
A system that's wrong 5% of the time and flags every uncertain output is far more useful than a system that's wrong 3% of the time and never tells you.
Field-level confidence scoring: the missing layer in document processing
When we built anyformat, the single most important architectural decision we made wasn't about which model to use or how to parse PDFs. It was this: every extracted value must carry a confidence score, and those scores must be calibrated against real human judgments.
What does that mean in practice?
The system doesn't just say "the invoice total is €14,320." It says "the invoice total is €14,320, and I'm 98.2% confident about that." For another field on the same document, it might say "the PO number is AT-2024-0892, and I'm 71% confident."
The 98.2% field gets auto-approved. The 71% field gets routed to a human reviewer. The reviewer doesn't check the whole document — just the uncertain field. They see the value, they see the confidence score, and (as I'll discuss in the next post) they see exactly where in the document the system read it.
This changes the economics of document processing entirely. Instead of reviewing 100% of extracted fields, your team reviews maybe 5–15%, depending on document quality. The rest flows through automatically — not because you've blindly trusted the AI, but because the AI has earned trust on a field-by-field basis.
But here's where it gets precise, and where most IDP vendors cut corners.
Why confidence calibration separates production IDP from demo-ware
A confidence score only means something if it's calibrated. When the system says "95% confident," that should correspond to being correct 95% of the time on fields where it reports that confidence level. Not 88%. Not 91%. Ninety-five.
Calibrating confidence scores requires a substantial corpus of human-labelled data. You need humans to annotate the correct values for thousands of documents, then compare the system's outputs and confidence levels against those human labels. The result is a calibration curve — a mapping between what the system claims its confidence is and what it actually is.
 Calibrated confidence means your auto-approval thresholds work as expected
Calibrated confidence means your auto-approval thresholds work as expected
A well-calibrated system produces a diagonal line: 70% confidence = 70% correct. 90% confidence = 90% correct. 99% confidence = 99% correct.
An uncalibrated system — which is what most tools produce — might say "95% confident" when the real accuracy at that threshold is 82%. Your team sets an auto-approval threshold at 95%, expecting 5% errors. They get 18%. Trust collapses. Back to the validation queue.
We've written in detail about how we score confidence in structured data, including the token-level probability analysis and multi-signal approach that makes calibration possible.
Confidence without calibration is decoration. It makes the output look trustworthy without actually being trustworthy.
5 metrics for evaluating document AI in production
If you're evaluating intelligent document processing solutions — or trying to understand why your current system isn't delivering — here are the metrics that actually predict production success:

1. Straight-through processing (STP) rate. What percentage of documents require zero human intervention? Not "zero errors" — zero touches. The document comes in, gets processed, and the structured output flows into your system without anyone looking at it. This is the metric that directly translates to headcount savings and processing speed. ABBYY's 2024 IDP benchmark puts the industry-average STP rate at 40–60% for invoice processing — top performers achieve 85%+.
2. Exception rate by field type. Not all fields are equal. Invoice numbers and dates tend to be high-confidence. Line item descriptions and tax codes tend to be lower. Understanding the exception rate by field type tells you where the system is strong, where it needs help, and where to focus improvement efforts.
3. Confidence calibration accuracy. Does 90% confidence actually mean 90% correct? If you can't verify this, your confidence scores are cosmetic. Ask your vendor for their calibration curve. If they don't have one, their confidence scores aren't calibrated.
4. Cost per document processed. This is the CFO metric. It includes everything: software cost, infrastructure cost, human review time, error correction time, and downstream cost of errors that slip through. A system with lower "accuracy" but better confidence scoring can have a dramatically lower cost per document — because it routes human attention only where it's needed.
5. Silent failure rate. How often does a wrong value get auto-approved? This should be tracked monthly and trend downward. If it isn't trending down, the system isn't learning from corrections.
The honest conversation about document AI accuracy
I'll be direct about something. anyformat isn't perfect on every document. No system is. The difference is that we know where we're imperfect, and we tell you.
Our confidence scores are calibrated against human-labelled datasets spanning thousands of document types across invoices, contracts, purchase orders, and customs declarations. When we say 97% confidence, we mean it — we've verified it against thousands of human annotations. When the system encounters a document that's genuinely hard — bad scan quality, unusual layout, ambiguous handwriting — the confidence drops and the field gets flagged for review.
That's not a limitation. That's how trust works.
The companies that escape the extraction trap don't have more accurate AI. They have AI that's honest about its own limitations. Paradoxically, that honesty is what makes real automation possible — because you can set thresholds, define rules, and build workflows around a system whose uncertainty you understand.
A system that's always confident is a system you can never fully trust. A system that knows when it doesn't know — that's infrastructure you can build on.
Frequently asked questions
What is straight-through processing (STP) in document AI?
Straight-through processing measures the percentage of documents that flow through an IDP system with zero human intervention — no manual review, no corrections. It's the single best indicator of real automation ROI, because it directly translates to processing speed and cost savings.
What is confidence calibration in intelligent document processing?
Confidence calibration means that a system's reported confidence scores match real-world accuracy. When a calibrated system says "95% confident," it is correct 95% of the time at that threshold. Uncalibrated systems may report 95% confidence while only being correct 80–85% of the time, leading to unexpected errors in production.
How do you measure silent failure rate in document processing?
Silent failure rate tracks how often a system extracts an incorrect value without flagging it for human review. It's measured by sampling auto-approved outputs and comparing them against human-verified ground truth. Best-in-class systems target a silent failure rate below 0.5%.
Why do document AI benchmarks not reflect production performance?
Benchmarks use curated datasets with clean, standard documents. Production environments include edge cases: poor scan quality, handwritten annotations, multilingual content, non-standard layouts. The gap between benchmark and production accuracy is typically 15–25 percentage points.
Next in the series: If You Can't Point to It, You Can't Trust It — why visual grounding is the foundation of auditable document AI.
Previously: The Paper Paradox: Why Document AI Still Hasn't Replaced Manual Work — what 100+ enterprise conversations taught me about document AI.
See how anyformat compares: vs Azure Document Intelligence · vs Extend AI · vs ChatGPT, Claude & Gemini · All comparisons →
Juan Huguet CEO & Co-founder, anyformat.ai
