
Long Documents Are the Production Case
Why 300-page PDFs break extraction systems, and how we solved it
TL;DR (May 2026). Bigger context windows do not solve long-document extraction. LLMs degrade in the middle of long inputs, naive chunking destroys multi-page tables, and the output side of frontier models is too small to return a parsed 300-page document in one call. anyformat ships a two-layer parse-extract architecture: page-level parsing in parallel, then an agentic extractor that reasons across all pages, rejoins multi-page tables, and returns document-level and table-level fields together in one schema-driven call.
In April 2026, Andrej Karpathy tried to convert a 245-page PDF using Microsoft's MarkItDown. The output came back mangled. His verdict on X, in a thread that crossed 100,000 views with Steph Ango from Obsidian: converting PDFs has to be "a Skill not a program" for a state-of-the-art LLM.
Karpathy co-founded OpenAI and led Autopilot AI at Tesla. He is not someone who quits on a technical problem. When he says long-document processing is unsolved, the document AI industry should pay attention.
We ran the same 245-page document through anyformat. No configuration. No stitching. No prompt gymnastics. Complex pages with bar charts, multi-column benchmark tables, mixed layouts. Structure intact. Tables intact. One call.
This article is about why long documents are hard, how the rest of the industry is approaching the problem, and the architecture we built to make 300-page extraction a production feature instead of a research project.
The default document is long, not short
Watch any extraction demo from any vendor. The PDF on screen is a one-page invoice. Clean layout, one table, twelve fields. Done in five seconds. Applause.
Now look at what enterprise document operations teams actually push through pipelines every day.
- Product catalogues at 200 pages with a single table that spans 40 of them.
- Financial filings at 300 pages with cover-page entity metadata and line-item tables starting on page 87.
- Insurance Evidence of Coverage documents that mix dense narrative with policy schedules.
- Customs declarations bundled with packing lists, certificates of origin, and commercial invoices in a single file.
- Multi-party contracts with appendices, schedules, and signature pages threaded across hundreds of pages.
These are not edge cases. They are the median document for any team serious about extraction at scale. If your IDP system only works on five-page inputs, it is a demo tool. It is not infrastructure.
Why long documents break the obvious approaches
There are three obvious ways to attack a long PDF with current technology. All three fail in production. The failure modes are well documented.
Approach 1: pour the whole document into an LLM
Drop a 300-page PDF into a vision-language model with a million-token context window. Let it figure out the structure. This is what every developer tries first. It breaks in four ways.
Token volume. A 300-page filing is 100,000 to 200,000 tokens once you include layout signal. Even when the model accepts the input, inference is slow and the per-document cost runs into dollars, not cents. Multiply by ten thousand documents a month and the bill is no longer a line item, it is a budget.
Output cap. Input windows have grown. Output windows have not. Frontier models still cap their output at a small fraction of what they will accept as input — typically a few thousand tokens, orders of magnitude less than what a parsed 300-page document needs to express. Even with a million-token input, you cannot get the answer back in one call. So you split the work across pages or sections, run them in parallel, and write the orchestration layer that keeps them in sync. That is no longer one model call. It is a distributed system, and the engineering work it takes to operate is exactly the work you reached for the LLM to avoid.
Lost in the middle. Liu et al. (2023) showed that LLMs degrade sharply when retrieving information from the middle of long contexts. The model reads the beginning well. It reads the end well. Accuracy collapses in the 20 to 80 percent range of the input. For a 300-page filing where the critical table starts on page 87, that is the entire payload.
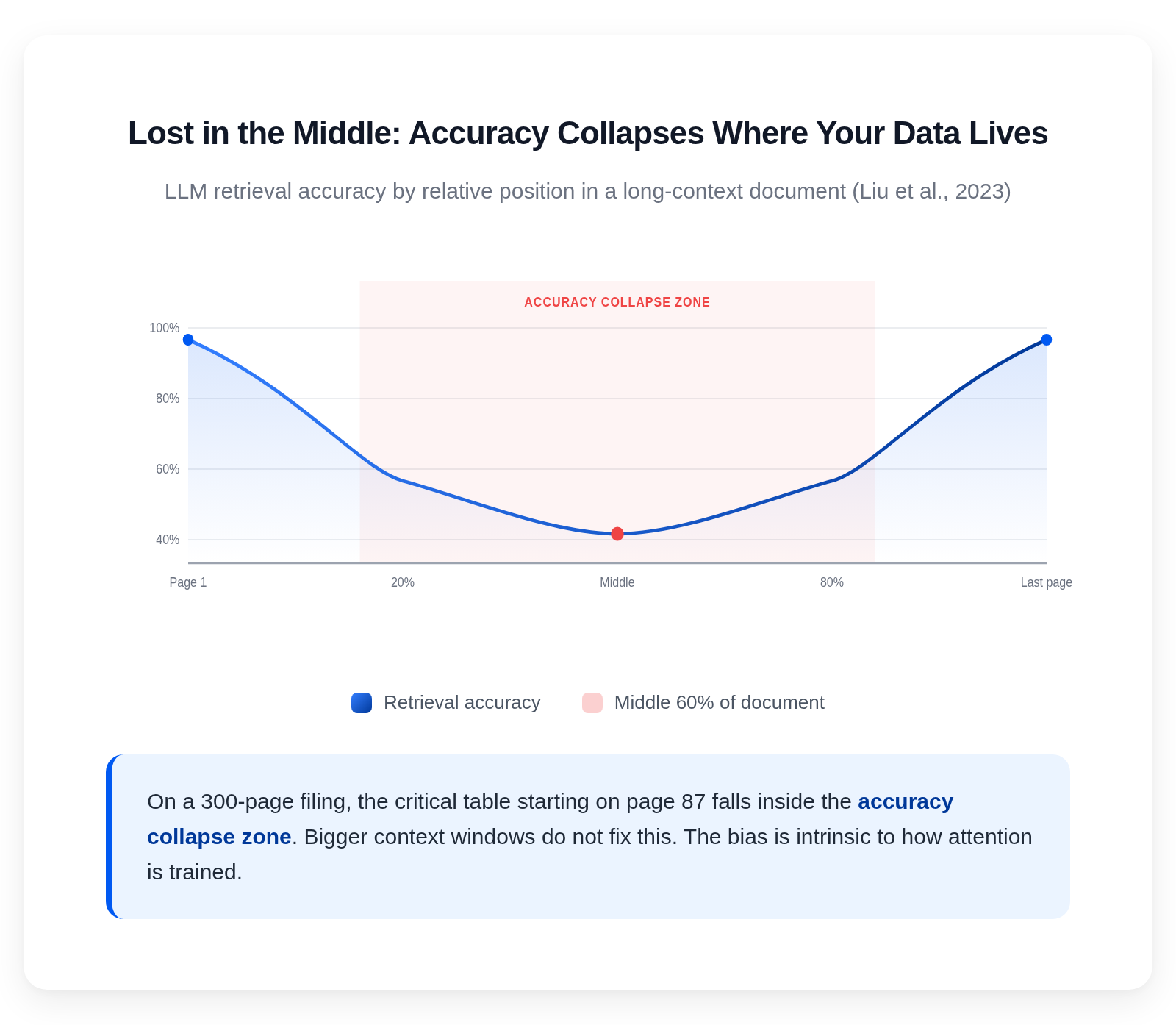 The U-shaped positional bias documented by Liu et al. (2023)
The U-shaped positional bias documented by Liu et al. (2023)
Latency. A single VLM call on a 200K-token document takes tens of seconds to minutes. Run a production pipeline at hundreds of documents per hour and you have a queue, not a service.
This is not theoretical. It is the wall every team hits the first time they try to ship.
Approach 2: chunk the document and process pages independently
The reflex fix is to split the PDF into pages or fixed-size chunks and process each one in isolation. This solves the context problem and creates four new ones.
Tables get cut. A table that runs from page 15 to page 22 becomes eight fragments with no link between them. Rows on page 18 do not know they belong to the same logical table as rows on page 16.
Headers repeat. Column headers print on every page. Chunks have no shared state, so they cannot dedupe. The output is rows of "Invoice Number, Date, Amount" appearing every five rows, treated as data.
Document-level fields drift away from the data. Supplier name on page 1. Line items on page 40. The chunk that sees page 40 has no idea who the supplier is. You end up joining downstream and praying nothing got swapped.
Stitching code becomes the product. Teams ship a thin wrapper around an extraction API and then write thousands of lines of post-processing: merge logic, deduplication heuristics, layout-specific glue. Every new supplier breaks it. Every format change breaks it. The pipeline is in permanent maintenance.
 Chunk-and-pray splits a 40-page table into 40 fragments. The reassembly job becomes the product.
Chunk-and-pray splits a 40-page table into 40 fragments. The reassembly job becomes the product.
Approach 3: semantic decomposition and parallel section extraction
The more sophisticated fix, and the one increasingly favoured in public posts by parsing vendors, is to split the document by semantic sections rather than fixed sizes, run extraction on each section in parallel, and merge results.
This is smarter than naive chunking. It is still not enough.
Section boundaries do not respect tables. If a contract appendix opens with the last three rows of the table from the previous section, the cut destroys the table. Merging requires a model that understands which fragments belong together, which is the original problem with extra steps. Document-level fields still need a separate pass because no single section contains them.
Where the field stands
We did not invent this taxonomy. Long-document extraction is a shared problem and the rest of the field has been working on it from a few different angles.
One family of approaches treats each row of a long table as an independent extraction target: run them in parallel, reassemble. It is a clever trade. You get exhaustive row coverage on tables that would otherwise lose rows in the middle. The cost is that document-level context lives somewhere else in the pipeline; the row-level call and the document-level call are not the same call.
Another family pushes against the LLM context window from a different direction: split the document by semantic sections, parse each section in parallel, merge the results. It is a careful piece of engineering. It also introduces risk at the boundaries when a table crosses a section.
Long-document extraction is not a context-window problem. It is an architecture problem. You cannot solve it by buying more tokens.
The diagnosis is shared. Lost-in-the-middle is real. Naive chunking is worse than no chunking. Semantic decomposition is a meaningful improvement on it. Each of these approaches makes a different cut at the same problem and each carries its own trade-offs.
What we wanted, and what we ended up building for, was table continuity across pages and document-level fields resolved together, in a single schema, in a single call. That is the angle we leaned into. We do not think it closes the book. The next step is parsing layers that natively merge multi-page tables, not just extractors that reason over them after the fact, and we expect everyone working in this space — ourselves included — to keep moving in that direction.
For vendor-specific trade-offs, see the comparison pages.
The architecture we built at anyformat
The core idea is that parsing and extraction are different jobs and should run on different layers. Most systems collapse them into a single LLM call. That is the mistake.
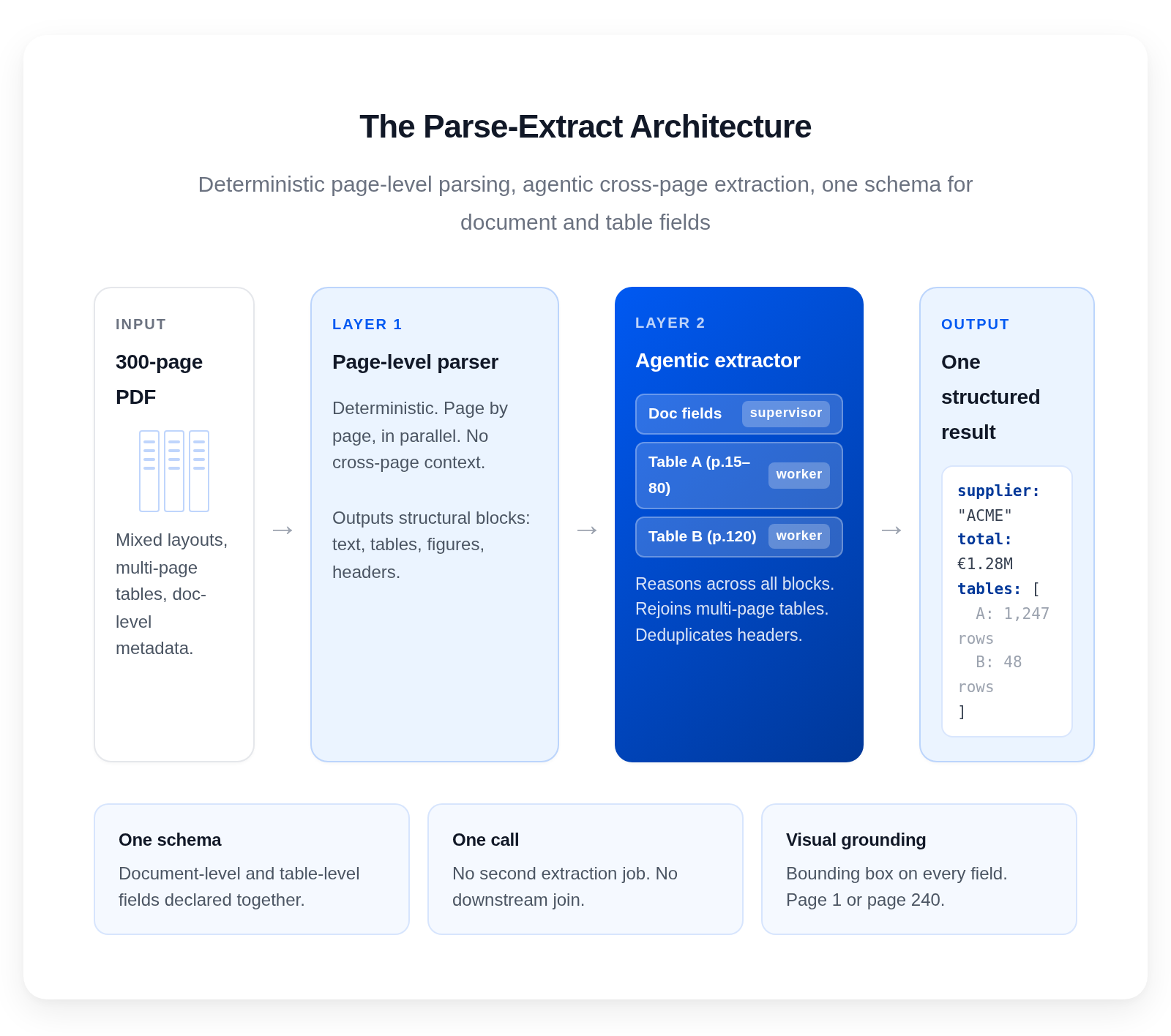 Two layers: page-level parsing in parallel, agentic cross-page extraction. One schema. One call.
Two layers: page-level parsing in parallel, agentic cross-page extraction. One schema. One call.
The parser works page by page, and block by block
The parser has no cross-page context. It looks at one page at a time and produces structural output for it. That is the obvious half of the design.
The less obvious half is what happens inside each page. A layout detector segments the page into discrete blocks — text regions, tables, figures, headers, footers, signatures — and defines the reading order across them. Then, block by block, the parser decides which can be read with code and which need a model to interpret well. A dense column of body text is read with code. A complex chart, a stamped signature, a handwritten note is handed to a model. Divide and conquer twice: once across pages, once across blocks. Accuracy climbs sharply because every block is solved in its own small context, not diluted in the noise of the whole page — and the context stays page-local, so the gains compound at scale.
This layer parallelises across pages with no coordination overhead. A 300-page document is 300 jobs that finish in seconds, the same way every time — which matters for audit.
This is the boring infrastructure layer. It is also the one most vendors get wrong, because they try to do too much at this stage.
The extractor reasons across the full set of parsed blocks
The extractor is where the intelligence lives. It operates across the full set of parsed blocks from every page in the document. It is agentic: a supervisor dispatches specialised workers depending on the requested schema. It coordinates extraction across pages. It runs code where code is the right tool. It calls the model where reasoning is the right tool.
For multi-page tables, the extractor detects table continuity across pages. It identifies which page-level table blocks belong to the same logical table and merges them into a single structure, preserving the original row order.
When a document contains multiple independent tables, each table gets its own worker. No cross-contamination. No accidental merging of unrelated tables that happen to share a column header.
One schema for document-level and table-level fields, together
The single most important design decision we made: one schema declares both document-level fields and table-level fields, and a single call returns both.
Supplier ID, contract reference, filing date, total amount. Those are document-level fields, even when the data lives on different pages. Line items, quantities, unit prices, tax codes. Those are table-level fields, even when the table spans forty pages.
You write one schema. We return one structured result containing both. Confidence scores on every field. Visual grounding on every field, meaning a bounding box that points to the exact source region the value came from, whether that source is on page 1 or page 240. This is the same visual grounding layer that makes our outputs auditable.
What this looks like in practice
A 150-page product catalogue with a table spanning 40 pages. Extracted as one table. All rows. No gaps. No stitching code in your pipeline.
A financial filing where the entity name is on page 1 and the line items span pages 15 to 80. Both returned in the same extraction result, from the same schema, in the same call. No second job. No downstream join.
A regulatory submission with three independent tables and a set of document-level metadata fields. Each table extracted separately, metadata attached. The output is structured data your downstream system can consume directly.
A 245-page report with bar charts, dense multi-column benchmark tables, and mixed layouts. Processed zero-shot. This is the document Karpathy could not convert. We can show it to you.
Why this matters for document operations and engineering teams
If you run a document operations team, your job is to deliver structured data to downstream systems with confidence scores, audit trails, and a flat per-document cost. Long-document support is the difference between hiring six people to babysit a pipeline and running the pipeline as infrastructure.
If you are an engineering team building a product on top of document extraction (fintech, insurtech, legaltech, supply chain, any vertical with regulated paperwork), long-document support is the difference between shipping your product and spending the next eighteen months writing glue code. The reason teams keep firefighting PDF pipelines is not lack of effort. It is that the underlying extraction layer forces them to.
We are one of the few vendors in the world with an architecture that handles 300-page documents zero-shot in a single call with document-level and table-level fields in one schema. We built it because our customers needed it, and because the obvious alternatives keep failing in public.
Frequently asked questions
Why do LLMs fail on long PDF extraction?
Long contexts trigger a U-shaped positional bias documented by Liu et al. (2023): accuracy is high at the beginning and end of the input and drops sharply in the middle. A 300-page PDF places most of its critical content in that low-accuracy region. Token volume also makes per-document cost and latency uneconomic at production scale.
What is lost-in-the-middle in document AI?
Lost-in-the-middle describes the phenomenon where large language models retrieve information reliably from the start and end of a long context but degrade significantly when the relevant content sits in the middle. It is the single biggest failure mode for end-to-end LLM extraction on long documents and shapes how the field designs around long inputs.
Why does naive chunking break tables in document extraction?
Fixed-size or page-level chunking processes each chunk in isolation. A table that spans multiple pages gets cut into independent fragments. The system has no shared state to rejoin rows or deduplicate repeated column headers, so the output requires custom stitching logic per document type, which breaks every time the layout changes.
How does anyformat handle 300-page document extraction?
anyformat separates parsing and extraction into two layers. The parser runs page by page in parallel: a layout detector segments each page into blocks and reading order, then the parser decides per block whether code or a model is the right tool. An agentic extractor then reasons across the full set of blocks, detects table continuity across pages and merges multi-page tables into a single structure, and returns document-level and table-level fields together in a single schema-driven result with confidence scores and visual grounding on every field.
Can I extract document-level and table-level fields in the same call?
Yes. anyformat is designed around a single schema that declares both. The supplier name on the cover page and the line items spanning page 40 to page 80 come back in the same structured response. You do not need a second extraction pass or a downstream join.
Long documents are not an edge case. They are the production case. If your team is firefighting PDFs instead of building product, we should talk.
Explore the documentation. See the architecture in Studio. Or write directly: juan@anyformat.ai.
See how anyformat compares: vs LlamaParse · vs Reducto · vs Unstructured · All comparisons →
Juan Huguet CEO & Co-founder, anyformat.ai
