
If You Can't Point to It, You Can't Trust It
From Pilot to Production · 03
Only 36% of enterprises say their document AI systems can trace extracted values back to the source document. The rest operate blind — extraction without evidence, automation without auditability. In a regulatory landscape shaped by the EU AI Act, GDPR, and DORA, that gap is becoming untenable.
A prospect showed me something last year that I keep thinking about.
They'd been using a document AI tool for six months. It was working — mostly. Extraction rates were decent, the team had adjusted to the validation workflow, and invoices were flowing into their ERP faster than before.
Then an internal audit happened.
The auditors pulled a sample of processed invoices. Standard procedure. They wanted to verify a set of extracted totals against the source documents. The system had the numbers. The structured data was clean. But when the auditors asked the obvious question — "where in the document did this value come from?" — nobody could answer.
The system couldn't show its work.
Not "wouldn't." Couldn't. The extraction tool produced outputs — invoice number, date, total, line items — but there was no link back to the source. No way to point at a region in the PDF and say "the system read this number from this cell in this table on this page." The connection between input and output was invisible.
They didn't fail the audit because the numbers were wrong. They failed because they couldn't prove the numbers were right.
The black box problem at the heart of document AI
This isn't unusual. It's the default.
Most document extraction tools work like this: a document goes in, structured data comes out, and the relationship between the two is opaque. The system might use OCR, computer vision, language models, rule engines, or some combination — but the output is a flat set of key-value pairs with no provenance attached.
For a demo, this is fine. You show the input document, you show the extracted JSON, the buyer compares them visually, everyone agrees it looks correct.
For production, it's a problem. And the problem gets worse the more you scale.
At 100 documents a day, a human can spot-check by opening the source PDF and visually scanning for the extracted values. It's tedious but possible.
At 10,000 documents a day, nobody's checking anything. The output flows directly into your ERP, your payment system, your compliance reporting. If a value is wrong, you discover it when the payment bounces, the tax filing is rejected, or the auditor asks a question you can't answer.
This is the black box problem. Not in the theoretical AI ethics sense. In the very practical sense of: your system makes thousands of decisions a day about financial data, and you cannot inspect any of them.
Every governance framework in existence requires traceability. Extraction without grounding is governance without evidence.
What visual grounding actually means in document processing
Visual grounding is the capability of linking every extracted value to the exact bounding box region in the source document where the system found it — creating a traceable, auditable provenance chain from input to output.
Not page-level. Not paragraph-level. The specific bounding box — the precise coordinates — of the text, cell, or region that produced the output.
When the system extracts an invoice total of €14,320, it also stores: "I read this value from the cell at coordinates [x1, y1, x2, y2] on page 2 of the source document." When a human reviewer, an auditor, or an automated validation rule needs to verify that value, it can go directly to the source location. No searching. No guessing. No opening the PDF and scanning the page hoping to find where the number came from.
This sounds simple. Architecturally, it's anything but. It requires the extraction system to maintain a persistent mapping between its understanding of the document's structure and every output it produces. Most extraction pipelines are designed as one-way flows: document in, data out. Building grounding means keeping the entire spatial relationship alive through the pipeline, which adds complexity to every layer of the system.
We made this a foundational architectural decision at anyformat from day one. Not as a feature added later. As a design constraint that shaped how we built everything else.
Here's why.
Three things grounding makes possible that nothing else can
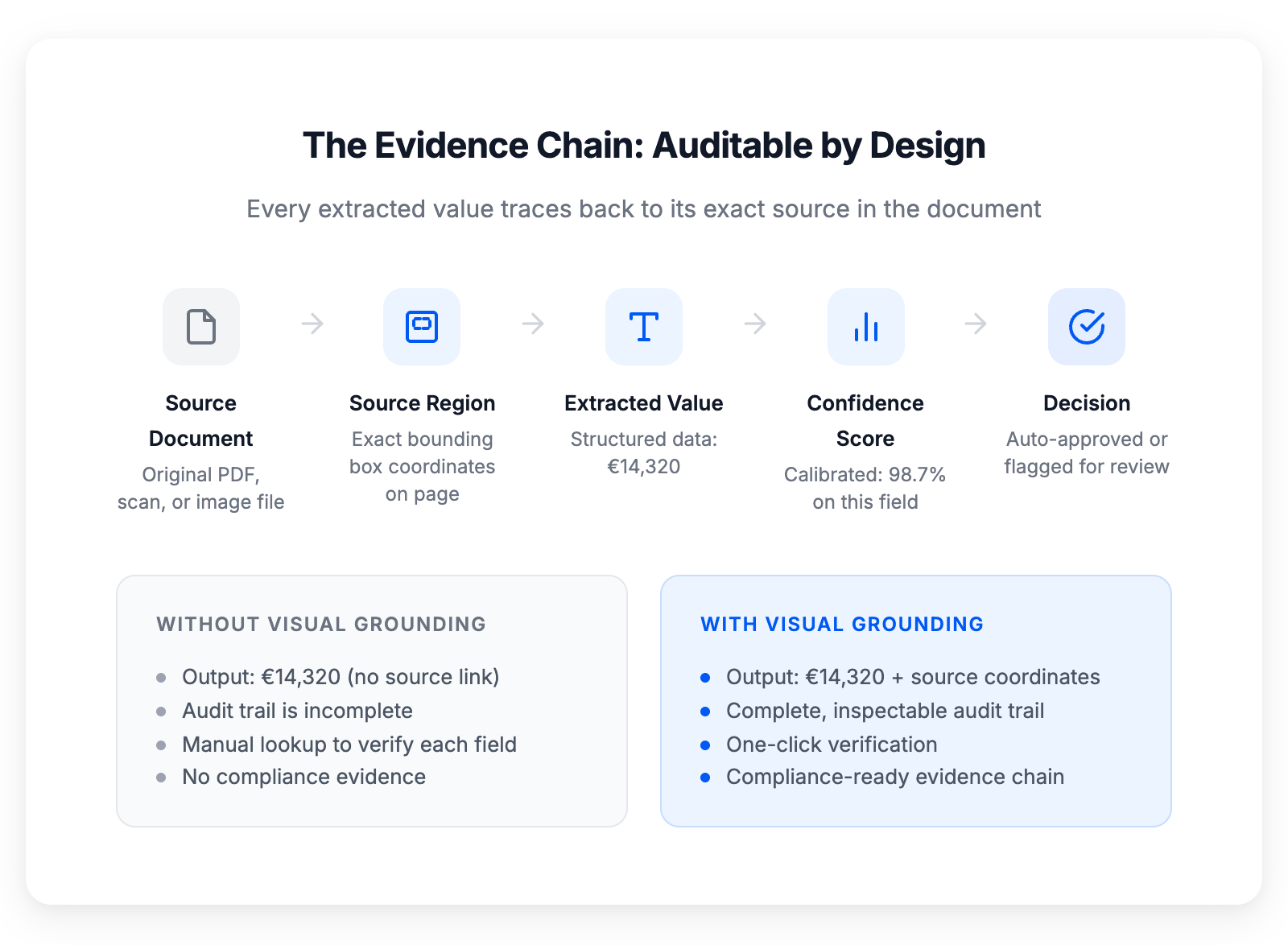 Visual grounding creates a complete, auditable evidence chain for every extracted value
Visual grounding creates a complete, auditable evidence chain for every extracted value
01 · Auditable automation for regulatory compliance
This is the obvious one, and it's the one that killed my prospect's audit. When every output links to its source, you have a complete chain of evidence: this document → this region → this value → this confidence score → this decision (auto-approved or human-reviewed). An auditor can follow that chain in seconds. Without it, they're reconstructing the logic from scratch — which is what "failing an audit" actually looks like in practice.
The regulatory pressure here is only increasing. The EU AI Act requires that high-risk AI systems (which includes systems making automated decisions about financial data) be transparent and explainable. GDPR's provisions on automated decision-making apply when automated processing affects individuals. The upcoming ViDA e-invoicing mandates will require traceable data lineage for cross-border transactions, with full rollout by July 2030. And DORA — the Digital Operational Resilience Act, enforceable since January 2025 — adds further traceability requirements for financial services firms across the EU.
Visual grounding isn't ahead of the regulation. The regulation is catching up to what production systems should have had all along.
02 · Faster, more focused human review
In the last post, I talked about field-level confidence scores — how a system that knows when it's uncertain lets your team review only the fields that need attention instead of everything.
Visual grounding makes that review dramatically faster.
When a field is flagged for human review, the reviewer doesn't just see the extracted value and the confidence score. They see the exact location in the source document where the system read it. They don't need to open the PDF and search. They don't need to remember what a PO number looks like on this supplier's invoice format. The system points directly to the source region.
The difference is measurable.
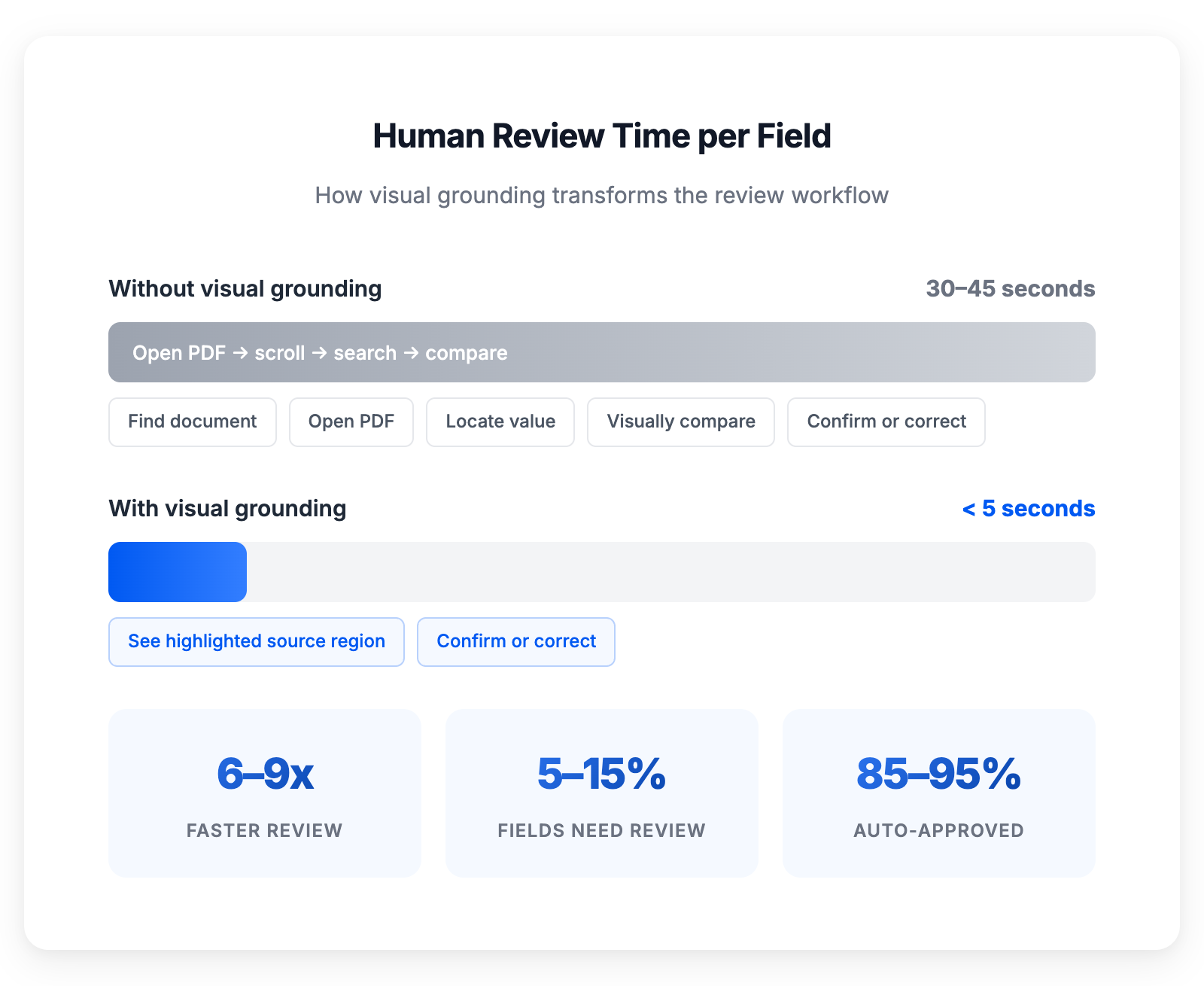 Visual grounding eliminates the search step, transforming review from a manual hunt into a one-glance confirmation
Visual grounding eliminates the search step, transforming review from a manual hunt into a one-glance confirmation
We've seen review times drop from 30–45 seconds per field (find the document, open it, locate the value, compare) to under 5 seconds (see the extracted value, see the source region, confirm or correct). At scale — thousands of fields per day that need review — that's the difference between a full-time review team and a part-time task. McKinsey puts the opportunity at 40% lower processing costs when document workflows are properly automated — and targeted human review through grounding is what makes "properly automated" possible.
03 · Continuous improvement through visible error patterns
When the system makes a mistake and a human corrects it, visual grounding tells you not just what went wrong but where and why.
The system misread a value. Where was it looking? Was it reading from the wrong cell? Did it confuse a subtotal with a total? Was the text in that region degraded from a bad scan? Did the layout shift compared to previous invoices from the same supplier?
Without grounding, error correction is blind — you know the output was wrong, but you can't see what the system saw when it made the mistake. With grounding, you can identify patterns: this supplier's invoices consistently cause errors in the tax code field because their layout places it in an unusual position. That's actionable. You can refine the system's behavior, or flag that supplier's invoices for automatic human review on that specific field.
Error patterns become visible. Improvement becomes systematic instead of random.
A system that can't show where it looked can't explain why it was wrong. Visual grounding turns error correction from guesswork into engineering.
The cost of not having visual grounding
I want to be concrete about what this looks like when it's missing, because the cost isn't always obvious upfront.
 Same audit, same rigor — 90% less verification work
Same audit, same rigor — 90% less verification work
The audit scenario
A regulated company processes 50,000 invoices a year through their extraction tool. An external audit selects 200 for verification. Without grounding, someone on the team has to manually open each source document, find each extracted value, and document the match. At 15–20 minutes per invoice for thorough verification, that's 50–65 hours of work. Every audit cycle. With grounding, the same verification takes 1–2 minutes per invoice because the link between output and source is already there. That's 3–6 hours. Same audit, 90% less work.
The trust erosion scenario
The extraction system makes an error that flows into a payment. The payment is wrong. The finance team investigates. They find the extracted value. They open the source document. They can't tell where the system read the number from — because the system doesn't store that information. Was it a system error? A document quality issue? A genuine ambiguity in the source? They can't tell. They log the error, correct the payment, and move on. But the team's confidence in the system drops. They start checking more outputs manually. Within a few months, the "automated" process has a growing manual review layer that wasn't in the original plan and isn't in the budget.
The compliance scenario
EU AI Act Article 14 requires human oversight for high-risk AI systems, including the ability for humans to understand the system's output and intervene when necessary. Article 13 requires transparency — users must be able to interpret the system's output appropriately. Without grounding, interpretation means opening the source document and hoping you can figure out what the system did. With grounding, interpretation is designed into the output. This isn't theoretical regulatory risk. The AI Act enforcement begins in phases starting 2025, with full application by August 2027.
What we see in practice
I'll share something specific from how this works at anyformat.
When our system processes a document, every extracted field carries three things: the value, the confidence score, and the grounding coordinates. The grounding isn't an approximation — it's the precise bounding box of the source text in the original document.
In our review interface, when a field is flagged for human attention, the reviewer sees the extracted value on one side and the source document on the other, with the relevant region highlighted. They don't search. They don't scroll. They look at the highlighted region, compare it to the extracted value, and confirm or correct. The entire interaction takes seconds.
When they correct a value, the correction is stored alongside the original extraction and the grounding data. This creates a feedback loop: we can analyze which document regions, which layouts, which field types produce the most corrections, and improve the system's behavior on exactly those cases.
The grounding data also flows downstream. When the structured output enters your ERP or payment system, the provenance travels with it. An auditor looking at a processed invoice in your system can trace any value back to its source region in the original document — without ever touching the extraction tool directly.
This is what "auditable by design" means. Not a feature you enable. An architectural property that exists in every output the system produces.
The deeper principle: inspectability builds trust
There's a pattern in how engineering systems earn trust. It's not by being right more often — although that matters. It's by being inspectable.
The systems we trust most in the physical world are the ones we can examine. We trust bridges not because we believe they'll never fail, but because we can inspect every weld, every beam, every foundation. We trust aircraft not because we assume perfection, but because every component has a traceable manufacturing history and every flight produces auditable maintenance data.
Document AI should work the same way. Not "trust us, the AI is very smart." But "here's exactly what the system read, here's exactly where it read it, here's how confident it is, and here's the evidence chain."
Trust, by design.
Frequently asked questions
What is visual grounding in document AI?
Visual grounding means every extracted value is linked to the exact bounding box coordinates in the source document where the system found it. Rather than producing opaque key-value outputs, a grounded system shows precisely which region on which page produced each value — making every extraction inspectable and verifiable.
Why is visual grounding important for document audit compliance?
Regulatory frameworks including the EU AI Act, GDPR, and DORA require that AI systems processing financial data be transparent, explainable, and auditable. Visual grounding provides the evidence chain auditors need: source document → source region → extracted value → confidence score → decision. Without it, organizations face compliance gaps and audit failures.
How does visual grounding reduce human review time in document processing?
With visual grounding, reviewers see the extracted value alongside the highlighted source region in the original document. This eliminates manual searching, reducing per-field review time from 30–45 seconds to under 5 seconds. At scale, this transforms full-time review teams into part-time monitoring roles.
What does the EU AI Act require for document processing transparency?
The EU AI Act classifies AI systems that process financial documents as high-risk. Article 13 requires sufficient transparency for deployers to interpret outputs appropriately. Article 14 requires human oversight capabilities. Full application for high-risk systems begins August 2027.
What is the difference between visual grounding and standard OCR?
Standard OCR converts images of text into machine-readable characters but typically doesn't maintain a persistent link between extracted values and their source locations. Visual grounding goes further: it preserves the exact coordinates and spatial context for every output, creating a traceable provenance chain from the source document to the structured data.
How does visual grounding support EU AI Act compliance for document processing?
The EU AI Act classifies AI systems processing financial documents as high-risk. Article 13 mandates transparency so deployers can interpret outputs. Article 14 requires human oversight with the ability to understand and intervene. Visual grounding directly satisfies both requirements by linking every output to its source evidence. Enforcement begins August 2027 for high-risk systems.
What is explainable AI (XAI) in document processing?
Explainable AI refers to AI systems whose decisions can be understood, inspected, and verified by humans. In document processing, this means the system can show not just what it extracted, but where in the source document it found each value and how confident it is. Visual grounding is the primary mechanism for achieving explainability in intelligent document processing.
Next in the series: The Training Tax — why the best document AI is the one you don't have to teach.
Previously: Beyond Accuracy: The Document AI Metrics That Actually Predict Production Success — what to measure instead when your documents actually matter.
Series start: The Paper Paradox: Why Document AI Still Hasn't Replaced Manual Work — what 100+ enterprise conversations taught me about document AI.
Send us your ugliest documents →
See how anyformat compares: vs Azure Document Intelligence · vs ABBYY · vs Google Document AI · vs ChatGPT, Claude & Gemini · All comparisons →
Juan Huguet · CEO & Co-founder, anyformat.ai · Nuclear Engineer · Physics PhD
