
Smart Lookup: Reference Data, Without the Brute Force
Document intelligence is not just document parsing. Smart Lookup is the operator that turns reference data workflows from context-window gambling into structured, traceable queries.
The market has settled on a comfortable shorthand: document intelligence is document parsing. Point an engine at a stack of files, get structured data back. Parsing is hard. Pulling clean, structured fields out of messy, multi-format, multi-layout documents is one of the harder problems in applied AI, and we work at it every day. We are not going to pretend otherwise.
But parsing, done well, is still only the first step of any real workflow. Real document operations almost never end at extraction. They cross-reference. They enrich. They validate against reference data that lives elsewhere, in spreadsheets, ERP exports, supplier catalogs, internal pricing tables. The structured output of a parser is rarely the answer on its own. It is a question that needs to be matched against a larger source of truth.
This is where most pipelines quietly break. The reader has probably built one. It extracts well. Then someone tries to reconcile the output against a reference file with thousands of rows, and the system stops behaving like infrastructure and starts behaving like a science experiment.
Why dumping the file into context fails
The default solution is the same everywhere. Load the entire reference file into the language model's context window, paste the extracted data next to it, and ask the model to find the match. It is the path of least resistance. It is also the path that does not scale.
Four things go wrong. The first is accuracy. Large context windows perform worse than the benchmarks suggest the moment the data inside them looks like real production reference data. The needle-in-a-haystack problem is well documented, and it gets worse when the haystack is a list of structurally similar records and the needle is a near-duplicate. Models lose precision in exactly the situations where precision matters most.
The second is cost. Every run sends the entire reference file through the model. Token consumption scales linearly with file size and document volume. What looks affordable at a hundred documents stops being affordable at a hundred thousand.
The third is auditability. When a model searches an embedded haystack and emerges with a match, there is no record of what it considered or why it chose what it chose. The output is a single value with no chain of reasoning behind it. In a regulated workflow, that is not a result. It is a guess wearing a tie.
The fourth is the ceiling itself. Context windows are large, but they are not infinite. Real reference data eventually exceeds them, and the workaround stops working entirely, with no graceful degradation.
Smart Lookup: structured queries, not brute force
Smart Lookup is a new operator in the anyformat platform, and it is built around a different premise. Instead of asking a model to find a needle inside a haystack, it asks the platform to retrieve the needle and hand the model exactly that. The model never sees the haystack.
In practice, Smart Lookup works in three stages. It reads the extracted data from the document and identifies the values that act as lookup keys. It constructs a structured query against the reference dataset, retrieves the candidate records that match, and hands those candidates to the model as the focused result set. The model then reasons over a handful of rows, not thousands, and produces a match along with a confidence score and a full trace of what was considered.
The contrast with the previous approach is architectural, not cosmetic. The old pattern was: load everything, hope the model finds it. The new pattern is: query, retrieve, reason, trace. The model works with tens of rows instead of tens of thousands. The reference data lives where reference data should live, in a structured store the platform queries on demand. The context window is freed for the work it is good at, which is reasoning over a focused set of inputs.
This is not a prompt engineering trick. It is a different shape of system. The naive approach treats the language model as a search engine and a reasoner at the same time, which is the role it is worst at. Smart Lookup separates those concerns. The platform does the retrieval. The model does the judgement. Each component does the job it is built for, which is the only way these systems hold up at scale.
From product name to SKU
A purchase order arrives. The parser turns the page into structured fields: line by line, quantity, unit price, product name. The names are written by humans, and they are useful to a person reading the page. They are not useful as a key into anything downstream.
The receiving ERP does not care about names. It cares about SKUs. The product master, the inventory levels, the pricing agreements: all of it lives behind a SKU. Until each line is reconciled to a SKU, it cannot trigger a goods receipt, update inventory, or post to the ledger.
This is the cross-reference Smart Lookup is built for. It takes each extracted product name as a lookup key, queries the product master, and retrieves the candidate SKUs that match. The model receives a focused set of candidates instead of the whole catalog, and selects the right SKU for each line, with a confidence score and a trace of what was considered along the way.
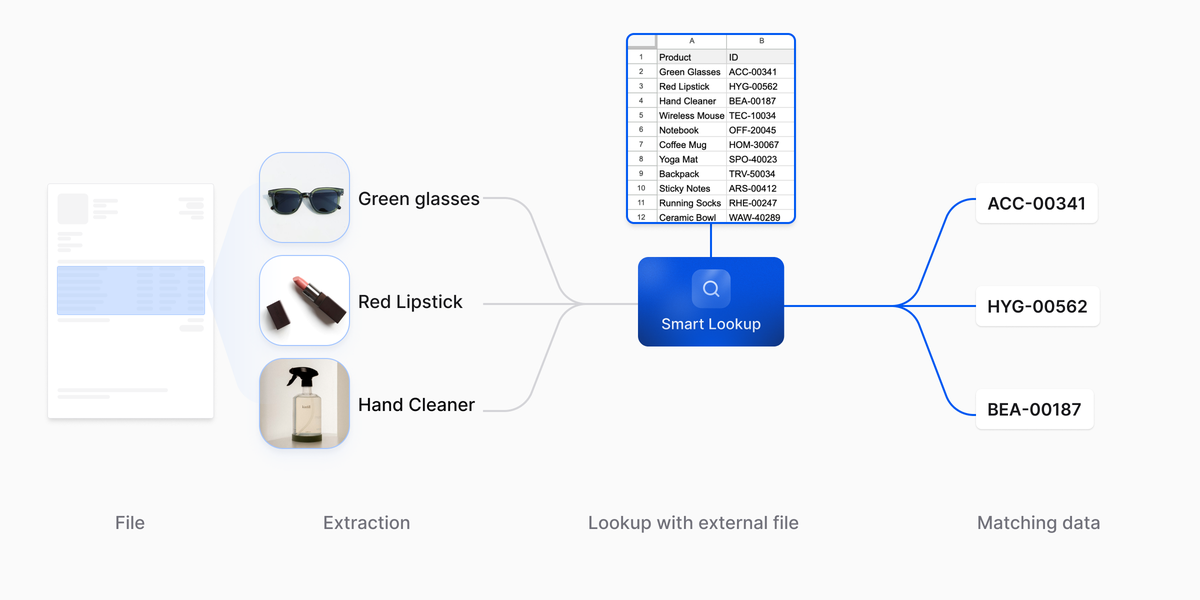
The matched SKUs flow into the ERP integration downstream. When confidence falls below the threshold the workflow sets, the line routes to human review instead of going through silently. When something needs to be verified after the fact, the trace shows the candidates Smart Lookup considered and the reason one was picked. That is the difference between a structured cross-reference and a guess.
What this enables
Because Smart Lookup is an operator in anyformat's workflow system, it composes with every other operator on the canvas. Extraction feeds it. Validation reads from it. Classification can route on its output. It is not a sidecar service. It is a step in the same pipeline as everything else, with the same execution model, the same logging, and the same auditability.
What that composability enables is straightforward to describe and hard to do without the right architecture underneath. Cross-referencing at scale, against datasets that would not fit in any context window, with no degradation of accuracy as the reference data grows. Every lookup produces a trace that names the query, the candidates considered, the selected match, and the confidence assigned to it. When something breaks in production, and in production something always breaks, the path from symptom to cause is a sequence of clicks on a canvas, not a forensics exercise on a log file.
Lower token consumption follows from the same architecture. The model processes a handful of candidates instead of an entire dataset, and the cost curve flattens out. Throughput rises for the same reason. None of these are marketing claims layered on top of a feature. They are consequences of the decision to stop asking the model to do what the platform should be doing, and to let each component do what it is good at.
The standard we are building toward
The deeper shift Smart Lookup represents is the move from "throw everything at the model" to "give the model exactly what it needs." That distinction sounds small. It is the difference between a system that demos well and a system that holds up under regulated load for years.
This is what document intelligence infrastructure looks like when it is built beyond parsing. Operators that compose. Reference data that lives where it should. Traces that survive an audit. A platform where the architectural decision is the product.
Smart Lookup is live in the anyformat platform today. The standard we are building toward is a quiet one: pipelines that work the same on the hundred-thousandth document as they did on the first.
anyformat is the document intelligence platform that turns unstructured documents into reliable, structured data, with enterprise-grade security, confidence scoring, and full auditability. Learn more at anyformat.ai.
