
Los documentos largos son el caso real de producción
Por qué los PDF de 300 páginas rompen los sistemas de extracción, y cómo lo hemos resuelto
TL;DR (mayo 2026). Las ventanas de contexto más grandes no resuelven la extracción de documentos largos. Los LLMs degradan en la mitad de entradas largas, el chunking ingenuo destroza las tablas multi-página, y la ventana de salida de los modelos frontera es demasiado pequeña para devolver un documento de 300 páginas parseado en una sola llamada. anyformat ofrece una arquitectura parse-extract en dos capas: parsing a nivel de página en paralelo, y después un extractor agentivo que razona sobre todas las páginas, reúne tablas multi-página y devuelve campos a nivel de documento y de tabla juntos en una única llamada por esquema.
En abril de 2026, Andrej Karpathy intentó convertir un PDF de 245 páginas con MarkItDown, la herramienta de Microsoft. El resultado salió destrozado. Su veredicto en X, en un hilo con Steph Ango (fundador de Obsidian) que superó las 100.000 visualizaciones, fue claro: convertir PDF tiene que ser "una Skill, no un programa" para un LLM de última generación.
Karpathy cofundó OpenAI y dirigió la IA de Autopilot en Tesla. No es alguien que abandone un problema técnico a la primera. Cuando dice que el procesamiento de documentos largos sigue sin resolverse, el sector de document AI debería tomar nota.
Nosotros procesamos el mismo documento de 245 páginas con anyformat. Sin configuración. Sin stitching. Sin malabarismos con prompts. Páginas con gráficos de barras, tablas de benchmark de varias columnas, layouts mixtos. La estructura intacta. Las tablas intactas. Una sola llamada.
Este artículo va de por qué los documentos largos son difíciles, cómo está abordando el problema el resto del sector, y la arquitectura que hemos construido para que la extracción a 300 páginas sea una característica de producción y no un proyecto de investigación.
El documento por defecto es largo, no corto
Mira cualquier demo de extracción de cualquier proveedor. El PDF que sale en pantalla es una factura de una página. Layout limpio, una tabla, doce campos. Listo en cinco segundos. Aplausos.
Ahora mira lo que los equipos de operaciones documentales meten cada día por el pipeline.
- Catálogos de producto de 200 páginas con una sola tabla que ocupa 40.
- Cuentas anuales de 300 páginas con metadatos en la portada y líneas de detalle que arrancan en la página 87.
- Documentos de Evidencia de Cobertura de seguros que mezclan narrativa densa con tablas de pólizas.
- Declaraciones aduaneras que vienen con packing lists, certificados de origen y facturas comerciales en un único archivo.
- Contratos multipartes con anexos, schedules y firmas repartidas en cientos de páginas.
No son casos extremos. Son la mediana de cualquier equipo serio que hace extracción a escala. Si tu sistema IDP solo funciona con entradas de cinco páginas, es una herramienta de demo. No es infraestructura.
Por qué los documentos largos rompen los enfoques obvios
Hay tres formas obvias de atacar un PDF largo con la tecnología actual. Las tres fallan en producción. Los modos de fallo están documentados y los propios proveedores que construyen estos sistemas los reconocen cada vez más.
Enfoque 1: meterlo todo dentro de un LLM
Pasa un PDF de 300 páginas a un modelo vision-language con un millón de tokens de contexto. Que se las apañe el modelo para entender la estructura. Esto es lo que prueba cualquier dev la primera vez. Rompe por cuatro sitios.
Volumen de tokens. Un expediente de 300 páginas son entre 100.000 y 200.000 tokens cuando incluyes la señal de layout. Aunque el modelo acepte la entrada, la inferencia es lenta y el coste por documento se mide en euros, no en céntimos. Multiplica por diez mil documentos al mes y la factura deja de ser una partida, es un presupuesto.
Tope de salida. La ventana de entrada ha crecido. La de salida no. Los modelos frontera siguen limitando su salida a una fracción mínima de lo que aceptan como entrada — apenas unos miles de tokens, órdenes de magnitud por debajo de lo que necesita expresar un documento de 300 páginas parseado. Aunque la entrada acepte un millón de tokens, la respuesta no cabe en una sola llamada. Así que partes el trabajo en páginas o secciones, las lanzas en paralelo y escribes la capa de orquestación que las mantiene en sincronía. A esa altura ya no es una llamada a un modelo. Es un sistema distribuido, y el trabajo de ingeniería que cuesta operarlo es exactamente el que querías evitar al recurrir al LLM.
Lost in the middle. Liu et al. (2023) demostraron que los LLM degradan con fuerza cuando tienen que recuperar información del medio de un contexto largo. El modelo lee bien el principio. Lee bien el final. La precisión se hunde en la franja del 20 al 80 por ciento del documento. Si en un expediente de 300 páginas la tabla crítica empieza en la página 87, esa franja es todo el contenido que importa.
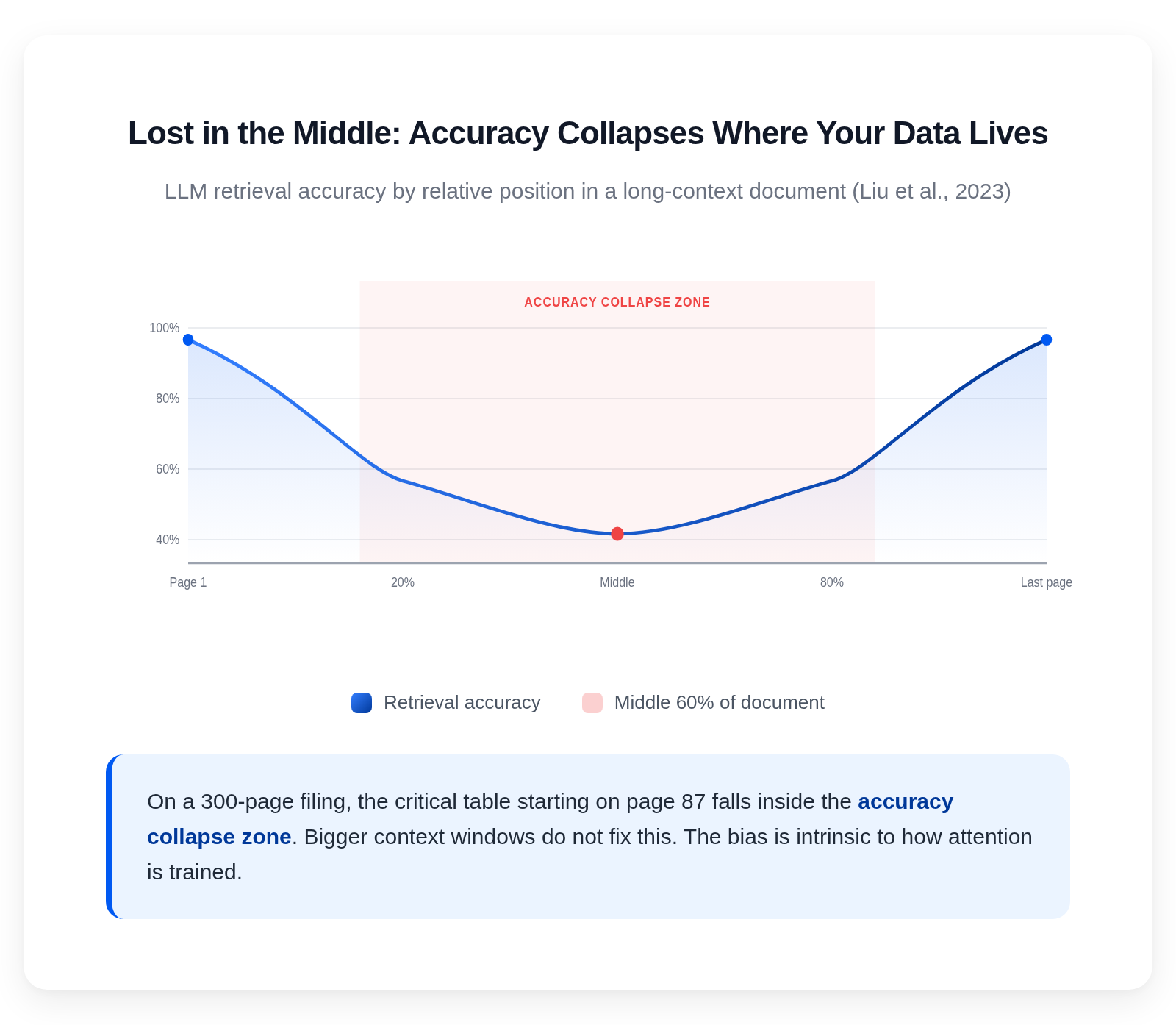 El sesgo posicional en U documentado por Liu et al. (2023)
El sesgo posicional en U documentado por Liu et al. (2023)
Latencia. Una sola llamada a un VLM con 200K tokens tarda decenas de segundos, a veces minutos. Pon un pipeline en producción a cientos de documentos por hora y lo que tienes es una cola, no un servicio.
Esto no es teoría. Es el muro que cualquier equipo encuentra la primera vez que intenta enviar a producción.
Enfoque 2: trocear el documento y procesar páginas de forma independiente
El parche reflejo es partir el PDF en páginas o en chunks de tamaño fijo y procesar cada uno aislado. Resuelve el problema de contexto y crea cuatro nuevos.
Las tablas se cortan. Una tabla que va de la página 15 a la 22 se convierte en ocho fragmentos sin conexión entre ellos. Las filas de la página 18 no saben que pertenecen a la misma tabla lógica que las filas de la página 16.
Las cabeceras se repiten. Las cabeceras de columna se imprimen en cada página. Los chunks no comparten estado, así que no pueden deduplicar. La salida son filas con "Número de factura, Fecha, Importe" apareciendo cada cinco filas, tratadas como datos.
Los campos a nivel de documento se desconectan de los datos. El nombre del proveedor está en la página 1. Las líneas, en la página 40. El chunk que ve la página 40 no tiene ni idea de quién es el proveedor. Acabas haciendo el join aguas abajo y rezando para que no se mezcle nada.
El código de stitching se convierte en el producto. Los equipos lanzan un wrapper finito sobre una API de extracción y después escriben miles de líneas de post-procesado: lógica de merge, heurísticas de deduplicación, pegamento específico por layout. Cada proveedor nuevo lo rompe. Cada cambio de formato lo rompe. El pipeline vive en mantenimiento perpetuo.
 Chunk-and-pray parte una tabla de 40 páginas en 40 fragmentos. Reconstruirla se convierte en el producto.
Chunk-and-pray parte una tabla de 40 páginas en 40 fragmentos. Reconstruirla se convierte en el producto.
Enfoque 3: descomposición semántica y extracción paralela por secciones
El parche más sofisticado, y el que cada vez aparece más en los posts públicos de los proveedores de parsing, consiste en partir el documento por secciones semánticas en vez de por tamaño fijo, ejecutar extracción en paralelo por sección y mezclar los resultados.
Es más inteligente que el chunking ingenuo. Sigue sin ser suficiente.
Las fronteras entre secciones no respetan las tablas. Si un anexo de contrato abre con las tres últimas filas de la tabla de la sección anterior, el corte destroza la tabla. Para hacer el merge bien necesitas un modelo que entienda qué fragmentos van juntos, que es el problema original con pasos extra. Los campos a nivel de documento siguen necesitando una pasada aparte porque ninguna sección los contiene completos.
Cómo lo está abordando el sector
Esta taxonomía no la hemos inventado nosotros. La extracción de documentos largos es un problema compartido y el resto del sector lleva tiempo trabajándolo desde ángulos distintos.
Una familia de enfoques trata cada fila de una tabla larga como un objetivo de extracción independiente: las lanza en paralelo y luego reensambla. Es un trade inteligente. Ganas cobertura exhaustiva en tablas donde, de otro modo, se perderían filas a mitad de documento. El coste es que el contexto a nivel de documento vive en otro sitio del pipeline; la llamada a nivel de fila y la llamada a nivel de documento no son la misma llamada.
Otra familia tira contra la ventana de contexto del LLM desde otra dirección: parte el documento por secciones semánticas, parsea cada sección en paralelo, hace merge. Es ingeniería cuidada. También introduce riesgo en las fronteras cuando una tabla cruza una sección.
La extracción de documentos largos no es un problema de ventana de contexto. Es un problema de arquitectura. No se resuelve comprando más tokens.
El diagnóstico se comparte. Lost-in-the-middle existe. El chunking ingenuo es peor que no hacer nada. La descomposición semántica es una mejora real sobre eso. Cada uno de estos enfoques hace un corte distinto al mismo problema y cada uno tiene sus propios trade-offs.
Lo que queríamos, y aquello para lo que terminamos construyendo, era continuidad de tablas entre páginas y campos a nivel de documento resueltos a la vez, en un mismo esquema, en una sola llamada. Es el ángulo por el que nos hemos decantado. No creemos que cierre el tema. El siguiente paso son capas de parsing que fusionen tablas multi-página de forma nativa, no solo extractores que razonen sobre ellas a posteriori, y esperamos que todos los que trabajamos en este espacio —nosotros incluidos— sigamos moviéndonos en esa dirección.
Para trade-offs específicos por proveedor, mira las páginas de comparativa.
La arquitectura que hemos construido en anyformat
La idea de fondo es que parsear y extraer son trabajos distintos y deben ejecutarse en capas distintas. La mayoría de sistemas los colapsan en una única llamada al LLM. Ahí está el error.
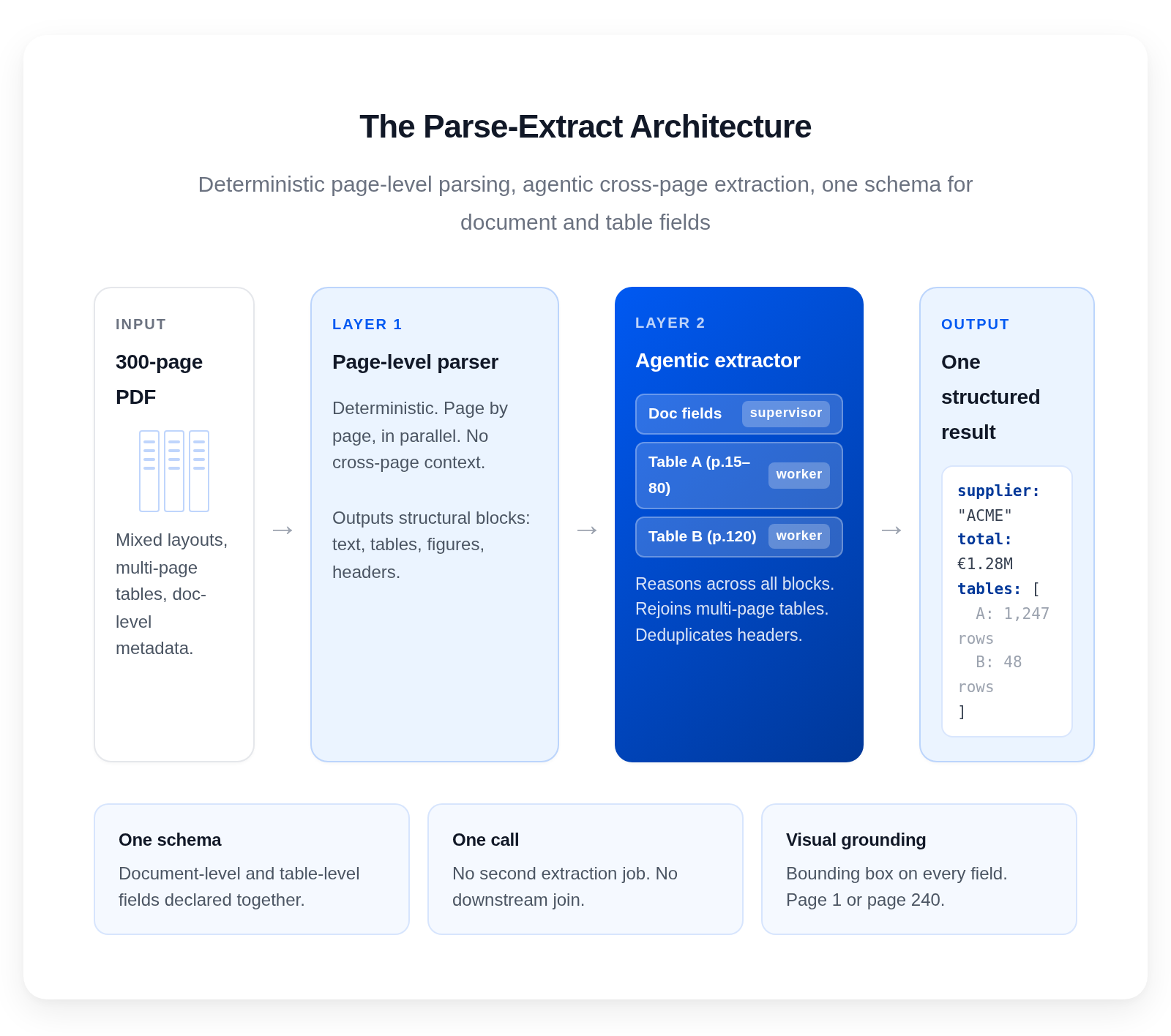 Dos capas: parsing a nivel de página en paralelo, extracción agentiva a través de todo el documento. Un esquema. Una llamada.
Dos capas: parsing a nivel de página en paralelo, extracción agentiva a través de todo el documento. Un esquema. Una llamada.
El parser trabaja página a página, y bloque a bloque
El parser no tiene contexto cruzado entre páginas. Mira una página cada vez y produce salida estructural para ella. Esa es la mitad evidente del diseño.
La mitad menos evidente es lo que pasa dentro de cada página. Un layout detector segmenta la página en bloques discretos —regiones de texto, tablas, figuras, cabeceras, pies, firmas— y define el reading order entre ellos. Después, bloque a bloque, el parser decide cuáles puede leer con código y cuáles necesitan un modelo para interpretarlos bien. Una columna densa de texto corrido se lee con código. Un gráfico complejo, una firma con sello, una nota manuscrita pasan al modelo. Divide y vencerás por partida doble: una vez entre páginas, otra dentro de cada página. La precisión sube de forma marcada porque cada bloque se resuelve en su propio contexto pequeño, no diluido en el ruido de la página entera — y ese contexto se mantiene local, así que las ganancias componen a escala.
Esta capa se paraleliza sobre todas las páginas sin overhead de coordinación. Un documento de 300 páginas son 300 jobs que terminan en segundos, igual cada vez — algo que importa para auditoría.
Esta es la capa de infraestructura aburrida. Es también la que la mayoría de proveedores hacen mal, porque intentan hacer demasiado en este paso.
El extractor razona sobre todos los bloques parseados
El extractor es donde vive la inteligencia. Opera sobre el conjunto completo de bloques parseados de todas las páginas del documento. Es agentivo: un supervisor despacha workers especializados según el esquema solicitado. Coordina la extracción entre páginas. Ejecuta código cuando el código es la herramienta correcta. Llama al modelo cuando el razonamiento es la herramienta correcta.
Para tablas multi-página, el extractor detecta la continuidad de la tabla entre páginas. Identifica qué bloques de tabla a nivel de página pertenecen a la misma tabla lógica y los une en una sola estructura, preservando el orden original de filas.
Cuando un documento contiene varias tablas independientes, cada tabla recibe su propio worker. Sin contaminación cruzada. Sin merges accidentales entre tablas no relacionadas que comparten una columna por casualidad.
Un esquema para campos de documento y de tabla, juntos
La decisión de diseño más importante que tomamos: un único esquema declara campos a nivel de documento y campos a nivel de tabla, y una única llamada devuelve los dos.
ID de proveedor, referencia de contrato, fecha de emisión, importe total. Esos son campos a nivel de documento, aunque los datos vivan en páginas distintas. Líneas, cantidades, precios unitarios, códigos de IVA. Esos son campos a nivel de tabla, aunque la tabla ocupe cuarenta páginas.
Tú escribes un esquema. Nosotros devolvemos un único resultado estructurado con las dos cosas. Confidence en cada campo. Visual grounding en cada campo, es decir, un bounding box que apunta a la región exacta del documento de la que sale el valor, esté esa región en la página 1 o en la 240. Es la misma capa de visual grounding que hace nuestras salidas auditables.
Qué aspecto tiene en producción
Un catálogo de producto de 150 páginas con una tabla que abarca 40. Extraída como una tabla. Todas las filas. Sin huecos. Sin código de stitching en tu pipeline.
Un expediente financiero con el nombre de la entidad en la página 1 y las líneas entre la 15 y la 80. Las dos cosas en el mismo resultado de extracción, desde el mismo esquema, en la misma llamada. Sin segundo job. Sin join aguas abajo.
Una presentación regulatoria con tres tablas independientes y un conjunto de metadatos a nivel de documento. Cada tabla extraída por separado, metadatos adjuntos. La salida son datos estructurados que tu sistema downstream puede consumir directamente.
Un informe de 245 páginas con gráficos de barras, tablas de benchmark densas a varias columnas y layouts mixtos. Procesado zero-shot. Ese es el documento que Karpathy no pudo convertir. Te lo podemos enseñar.
Por qué esto importa a los equipos de document operations e ingeniería
Si llevas un equipo de document operations, tu trabajo es entregar datos estructurados a los sistemas aguas abajo con confidence, trazabilidad de auditoría y un coste por documento plano. El soporte de documentos largos es la diferencia entre contratar a seis personas para vigilar un pipeline y ejecutar el pipeline como infraestructura.
Si eres un equipo de ingeniería construyendo un producto sobre extracción documental (fintech, insurtech, legaltech, supply chain, cualquier vertical con papeleo regulado), el soporte de documentos largos es la diferencia entre lanzar tu producto y pasarte los próximos dieciocho meses escribiendo código pegamento. Los equipos no apagan fuegos de PDF por falta de esfuerzo. Lo hacen porque la capa de extracción que están usando les obliga a hacerlo.
Somos uno de los pocos proveedores en el mundo con una arquitectura que procesa documentos de 300 páginas zero-shot en una sola llamada, con campos de documento y de tabla en un mismo esquema. Lo construimos porque nuestros clientes lo necesitaban y porque las alternativas obvias siguen fallando a la vista de todos.
Preguntas frecuentes
¿Por qué fallan los LLM en la extracción de PDF largos?
Los contextos largos disparan un sesgo posicional en forma de U documentado por Liu et al. (2023): la precisión es alta al principio y al final del contexto y cae con fuerza en el medio. Un PDF de 300 páginas coloca la mayor parte del contenido crítico en esa franja de baja precisión. El volumen de tokens también hace que el coste por documento y la latencia sean inviables a escala de producción.
¿Qué es lost-in-the-middle en document AI?
Lost-in-the-middle describe el fenómeno por el que los grandes modelos de lenguaje recuperan información de forma fiable al principio y al final de un contexto largo, pero degradan de forma significativa cuando el contenido relevante está en el medio. Es el modo de fallo principal de la extracción end-to-end con LLM sobre documentos largos y condiciona cómo el sector diseña alrededor de entradas largas.
¿Por qué el chunking ingenuo rompe las tablas en extracción documental?
El chunking de tamaño fijo o por página procesa cada chunk de forma aislada. Una tabla que ocupa varias páginas se parte en fragmentos independientes. El sistema no tiene estado compartido para reunir filas o deduplicar cabeceras repetidas, así que la salida requiere lógica de stitching por tipo de documento, que se rompe cada vez que el layout cambia.
¿Cómo maneja anyformat la extracción de documentos de 300 páginas?
anyformat separa parsing y extracción en dos capas. El parser corre página a página en paralelo: un layout detector segmenta cada página en bloques y reading order, y después el parser decide bloque a bloque si lo lee con código o si lo pasa a un modelo. Un extractor agentivo razona luego sobre el conjunto completo de bloques, detecta la continuidad de las tablas entre páginas y las fusiona en una sola estructura, y devuelve campos de documento y de tabla a la vez en un único resultado estructurado por esquema, con confidence y visual grounding en cada campo.
¿Puedo extraer campos a nivel de documento y a nivel de tabla en la misma llamada?
Sí. anyformat está diseñado en torno a un único esquema que declara los dos. El nombre del proveedor en la portada y las líneas que van de la página 40 a la 80 vuelven en la misma respuesta estructurada. No necesitas una segunda pasada de extracción ni un join aguas abajo.
Los documentos largos no son un caso extremo. Son el caso real de producción. Si tu equipo apaga fuegos de PDF en vez de construir producto, deberíamos hablar.
Explora la documentación. Mira la arquitectura en Studio. O escríbeme directamente: juan@anyformat.ai.
Cómo se compara anyformat: vs LlamaParse · vs Reducto · vs Unstructured · Todas las comparativas →
Juan Huguet CEO y cofundador, anyformat.ai
