
Smart Lookup: datos de referencia, sin fuerza bruta
La inteligencia documental no es solo parsing de documentos. Smart Lookup es el operador que convierte los flujos sobre datos de referencia, de jugársela con la ventana de contexto a consultas estructuradas y trazables.
El mercado se ha quedado con una versión cómoda del problema: inteligencia documental es lo mismo que parsing de documentos. Apuntas un motor a un montón de archivos y recibes datos estructurados. El parsing es difícil. Extraer campos limpios y estructurados a partir de documentos desordenados, multiformato y con diseños muy distintos es uno de los problemas más duros de la IA aplicada, y lo trabajamos a diario. No vamos a fingir lo contrario.
Pero el parsing, por bien hecho que esté, sigue siendo solo el primer paso de cualquier flujo real. Las operaciones documentales reales casi nunca terminan en la extracción. Cruzan datos. Los enriquecen. Los validan contra datos de referencia que viven en otro sitio: hojas de cálculo, exports de ERP, catálogos de proveedor, tablas internas de precios. La salida estructurada de un parser rara vez es la respuesta por sí sola. Es una pregunta que necesita encajarse contra una fuente de verdad más amplia.
Aquí es donde la mayoría de pipelines se rompen sin hacer ruido. Quien lee esto probablemente haya construido uno. Extrae bien. Después alguien intenta conciliar la salida contra un archivo de referencia con miles de filas, y el sistema deja de comportarse como infraestructura y empieza a comportarse como un experimento de laboratorio.
Por qué meter el archivo en el contexto no funciona
La solución por defecto es siempre la misma. Cargar el archivo de referencia entero en la ventana de contexto del modelo, pegar al lado los datos extraídos y pedir al modelo que encuentre la coincidencia. Es el camino de menor resistencia. También es el camino que no escala.
Cuatro cosas salen mal. La primera es la precisión. Las ventanas de contexto grandes rinden peor de lo que sugieren los benchmarks en cuanto los datos que contienen se parecen a datos de referencia reales de producción. El problema de la aguja en el pajar está bien documentado, y empeora cuando el pajar es una lista de registros estructuralmente parecidos y la aguja es un casi-duplicado. Los modelos pierden precisión justo en las situaciones donde la precisión más importa.
La segunda es el coste. Cada ejecución envía el archivo de referencia entero al modelo. El consumo de tokens escala linealmente con el tamaño del archivo y el volumen de documentos. Lo que parece asequible con cien documentos deja de serlo con cien mil.
La tercera es la auditabilidad. Cuando un modelo busca dentro de un pajar embebido y sale con una coincidencia, no queda registro de qué consideró ni por qué eligió lo que eligió. La salida es un valor único sin cadena de razonamiento detrás. En un flujo regulado, eso no es un resultado. Es una conjetura con corbata.
La cuarta es el techo en sí. Las ventanas de contexto son grandes, pero no infinitas. Los datos de referencia reales acaban superándolas, y el apaño deja de funcionar por completo, sin degradación gradual.
Smart Lookup: consultas estructuradas, no fuerza bruta
Smart Lookup es un nuevo operador en la plataforma de anyformat, y está construido sobre una premisa distinta. En lugar de pedirle a un modelo que encuentre una aguja dentro de un pajar, le pide a la plataforma que recupere la aguja y le entregue al modelo exactamente eso. El modelo nunca ve el pajar.
En la práctica, Smart Lookup funciona en tres etapas. Lee los datos extraídos del documento e identifica los valores que sirven como claves de búsqueda. Construye una consulta estructurada contra el dataset de referencia, recupera los registros candidatos que encajan, y los entrega al modelo como conjunto de resultados acotado. El modelo razona entonces sobre un puñado de filas, no miles, y produce una coincidencia junto con una puntuación de confianza y una traza completa de lo que se ha considerado.
El contraste con el enfoque anterior es arquitectónico, no cosmético. El patrón viejo era: cargarlo todo y esperar que el modelo lo encuentre. El patrón nuevo es: consultar, recuperar, razonar, trazar. El modelo trabaja con decenas de filas en lugar de decenas de miles. Los datos de referencia viven donde deben vivir, en un almacén estructurado al que la plataforma consulta bajo demanda. La ventana de contexto queda libre para el trabajo en el que es buena: razonar sobre un conjunto acotado de entradas.
Esto no es un truco de prompt engineering. Es otra forma de sistema. El enfoque ingenuo trata al modelo de lenguaje como buscador y razonador a la vez, que es justo el papel para el que peor funciona. Smart Lookup separa esas responsabilidades. La plataforma se encarga de la recuperación. El modelo se encarga del juicio. Cada componente hace el trabajo para el que está hecho, que es la única manera de que estos sistemas aguanten a escala.
Del nombre del producto al SKU
Llega una orden de compra. El parser convierte la página en campos estructurados: línea a línea, cantidad, precio unitario, nombre de producto. Los nombres los escriben personas, y son útiles para alguien que lee la página. No son útiles como clave hacia ningún sistema aguas abajo.
Al ERP receptor no le importan los nombres. Le importan los SKU. El maestro de productos, los niveles de inventario, los acuerdos de precios: todo eso vive detrás de un SKU. Mientras cada línea no se concilie contra un SKU, no puede disparar una recepción de mercancía, actualizar el inventario ni asentarse en la contabilidad.
Este es el cruce para el que Smart Lookup está hecho. Toma cada nombre de producto extraído como clave de búsqueda, consulta el maestro de productos y recupera los SKU candidatos que encajan. El modelo recibe un conjunto acotado de candidatos en lugar del catálogo entero, y selecciona el SKU correcto para cada línea, con una puntuación de confianza y una traza de lo que se ha considerado por el camino.
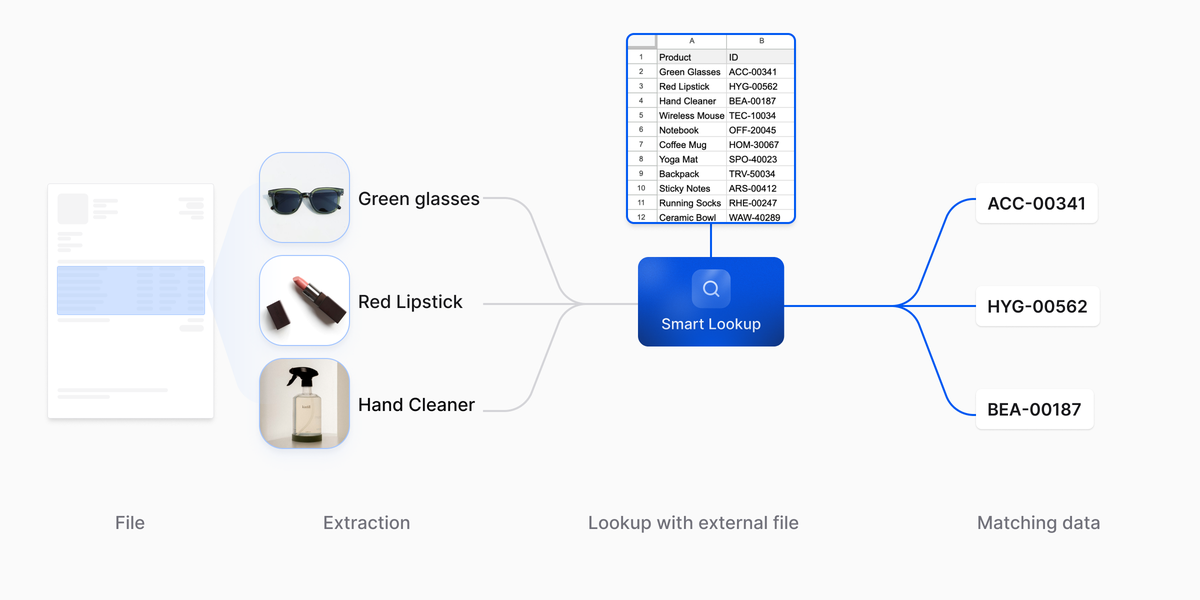
Los SKU emparejados pasan a la integración con el ERP aguas abajo. Cuando la confianza queda por debajo del umbral que fija el flujo, la línea se desvía a revisión humana en lugar de pasar en silencio. Cuando hay que verificar algo a posteriori, la traza muestra los candidatos que Smart Lookup consideró y la razón por la que se eligió uno. Esa es la diferencia entre un cruce estructurado y una conjetura.
Lo que esto habilita
Como Smart Lookup es un operador del sistema de flujos de anyformat, compone con cualquier otro operador del lienzo. La extracción lo alimenta. La validación lee de él. La clasificación puede enrutar según su salida. No es un servicio paralelo. Es un paso en el mismo pipeline que todo lo demás, con el mismo modelo de ejecución, el mismo logging y la misma auditabilidad.
Lo que esa composabilidad habilita es fácil de describir y difícil de hacer sin la arquitectura adecuada debajo. Cruzar datos a escala, contra datasets que no cabrían en ninguna ventana de contexto, sin degradación de la precisión a medida que los datos de referencia crecen. Cada búsqueda produce una traza que nombra la consulta, los candidatos considerados, la coincidencia elegida y la confianza que se le asignó. Cuando algo se rompe en producción, y en producción algo se rompe siempre, el camino del síntoma a la causa es una secuencia de clics en un lienzo, no un ejercicio forense sobre un log.
El menor consumo de tokens se deriva de la misma arquitectura. El modelo procesa un puñado de candidatos en lugar de un dataset entero, y la curva de coste se aplana. El throughput sube por la misma razón. Nada de esto son promesas de marketing montadas sobre una funcionalidad. Son consecuencias de la decisión de dejar de pedirle al modelo lo que debería hacer la plataforma, y de dejar que cada componente haga aquello en lo que es bueno.
El estándar hacia el que construimos
El cambio más profundo que representa Smart Lookup es el paso de «tirárselo todo al modelo» a «darle al modelo exactamente lo que necesita». La distinción suena menor. Es la diferencia entre un sistema que queda bien en una demo y un sistema que aguanta carga regulada durante años.
Esto es lo que parece la infraestructura de inteligencia documental cuando se construye más allá del parsing. Operadores que componen. Datos de referencia que viven donde deben vivir. Trazas que sobreviven a una auditoría. Una plataforma en la que la decisión arquitectónica es el producto.
Smart Lookup está disponible hoy en la plataforma de anyformat. El estándar hacia el que construimos es discreto: pipelines que funcionan igual con el documento número cien mil que con el primero.
anyformat es la plataforma de inteligencia documental que convierte documentos no estructurados en datos fiables y estructurados, con seguridad de nivel empresarial, puntuaciones de confianza y trazabilidad completa. Más información en anyformat.ai.
